OrdinalCLIP : Learning Rank Prompts for Language-Guided Ordinal Regression
https://arxiv.org/abs/2206.02338
OrdinalCLIP: Learning Rank Prompts for Language-Guided Ordinal Regression
This paper presents a language-powered paradigm for ordinal regression. Existing methods usually treat each rank as a category and employ a set of weights to learn these concepts. These methods are easy to overfit and usually attain unsatisfactory performa
arxiv.org
text와 image를 align시키는 contrastive learning에 대해 공부하고 있습니다.
이에 대한 선행 공부로 해당 논문에 대해 알아보게 되었습니다.
Abstract
이 논문에선 ordinal regression 방법에 대한 새로운 language-powered paradigm을 제시합니다.
기존의 방법들은 보통 각 rank (순위)를 카테고리로 다루고 각 순위를 표현하기 위해 weight set을 사용합니다. 이런 방법들은 overfitting 되기 쉽고 보통 학습된 rank 개념은 training data에만 의존하기 때문에 일반화 성능이 낮습니다. 최근 CLIP과 같은 거대한 pre-trained vision-language model들이 다양한 visual task에서 좋은 성능을 보였습니다. 이 논문에선, 풍부한 정보를 가진 semantic CLIP latent space로부터 rank의 개념을 학습할 수 있도록 했습니다. 구체적으로, 이 ordinal regression task를 contrastive objective를 사용한 image-language matching proble m으로 재정의했고, 이는 label을 text로 간주하고 각각의 rank에 대해 text encoder로부터 language prototype을 얻습니다. CLIP에 대해 prompt engineering하는건 시간이 매우 오래 걸리기 때문에, CLIP을 ordinal regression에 적용하기 위해 differentiable prompting method인 OrdinalCLIP을 제시합니다. OrdinalCLIP은 학습가능한 context token과 rank embedding으로 이루어집니다. 학습 가능한 rank embedding은 explicit하게 numerical continuity를 modeling해서 구성되고, 잘 순서화된, CLIP 공간에서의 압축된 language prototype을 얻습니다. 한 번 학습되면, language prototype만 저장하고 거대한 language model은 사용하지 않고, 결국 linear head counterpart와 비교했을 때 추가적인 computational overhead가 들지 않습니다.
정리
- 기존의 ordinal regression : 각 rank를 category로 간주. 각 rank에 대해 특정 weight를 학습 (training data에 의존)
- CLIP : large pre-trained vision-language model로 CLIP의 semantic latent space 활용 가능
- OrdinalCLIP : ordinal regression을 image-language matching 문제로 재구성. 각 rank(순위)를 text label로 간주. CLIP의 text encoder사용해 각 rank에 대한 language prototype(text embedding) 생성. 기존 CLIP의 prompt engineering은 시간이 많이 걸리기 때문에 Ordinal CLIP은 differentiable prompting 방법으로 진행.
- OrdinalCLIP의 구성 요소 : learnable context token + learnable rank embeddings
- rank embeddings : numerical continuity를 명시적으로 modeling -> CLIP space에서 잘 학습된 language prototype 생성
=> OrdinalCLIP은 CLIP의 latent space와 learnable prompting 활용해 ordinal regression task 해결. few-shot과 분포 변화 상황에서도 성능 개선 가능
CLIP에서 text encoder는 text를 vectorize해서 CLIP의 latent space에서 semantic 위치를 부여. 여기서 prototype은 특정 개념을 대표하는 vector로 여기선 순위(rank)와 같은 ordinal data를 CLIP의 language space에서 표현하는 vector
ex) 20살, 30살, 40살이라는 순위를 text로 변환 후, text encode로 embedding해서 얻은 vector들이 각각 language prototype이 됨
Introduction
ordinal regression의 가장 간단한 방법은 scale 값을 바로 regress하는 것입니다. 이는 single neuron으로 구성되거나 L1이나 L2 loss로 최적화됩니다. 그러나, 이는 제한된 성능을 냅니다. 이 중 몇 방법들은 보통 연속적인 target space를 다른 bin으로 이산화하거나 rank label을 다른 숫자로 다룹니다. 그리고 이런 discrete value를 다른 category로 다루고 linear layer를 사용해 classification을 수행합니다. 이런 방법들은 '순서에 대한 기념을 modeling하는 weight의 set'을 학습해야 합니다. 여기선 2가지의 문제가 있습니다.
1. rank를 독립적인 class category로 다루면 ordinal한 특성을 반영하기 어렵습니다.
2. training set으로부터 정보가 학습되기 때문에, overfitting되기 쉽습니다.
image domain으로부터만 rank 개념을 학습하는 것은 overfitting되기 쉽기 때문에, 이런 문제를 다루기 위해 multimodal 정보를 활용합니다. human language는 풍부한 semantic 정보와 prior knowledge를 포함합니다. 그렇기 때문에 이런 language domain을 통해 rank의 개념을 갖고올 수 있습니다. 각각의 rank label이 독립된 class category로만 다뤄지는게 아닌, "this person is 23 years old"처럼 해당 rank를 설명하는 sentence와 연결되게 됩니다. 이 방법으로, 이 논문에서 제시한 모델은 vision dataset에서 정의된 rank의 개념뿐만 아니라, language domain에서 공통으로 쓰이는 rank의 knowledge까지 이용할 수 있게 됩니다. 이 논문에서, ordinal regression을 위한 language-powered paradigm을 제시하고, 이는 잘 정의된 language latent space로부터 각 rank에 대해 language prototype을 학습합니다. 여기선 각 rank cateogry를 language concept고ㅠㅏ 연결지어 overfitting 문제를 다룰 수 있습니다. CLIP은 대규모의 image-text pair를 이용해 image encoder와 text encoder를 학습하고 language prior를 사용할 수 있도록 zero/few-shot knowledge transfer를 통해 좋은 성능을 얻을 수 있습니다. 구체적으로, 각 rank label을 text input(prompt)로 바꾸고 CLIP에 있는 pre-trained giant text encoder를 통해 모든 rank에 대해 language prototype을 추출합니다. 그리고 ordinal regression을 image-text matching framework로 재정의하고, image embedding은 학습가능한 image encoder로부터 얻고, language prototype의 set은 matching될 text feature로 여겨집니다. 여기선 image feature를 고정된 language space로 align하는 것을 목표로 합니다. prototype은 고정된 language model로부터 얻어지기 때문에, CLIP model로부터 간접적으로 language knowledge를 얻을 수 있게 됩니다. 뿐만 아니라 이런 prototype은 잘 학습된 language latent space에 제약되어 있기 때문에 generalization을 더 강하게 하는 regularization 역할도 할 수 있게 됩니다.
최근 연구는 text input(prompt)가 performance에서 중요한 하고 올바른 prompt를 선택하는 것에 상당히 많은 시간이 걸린다고 합니다. hard prompt를 사용하는 대신, ordinal regression을 위해 rank prompt를 학습합니다. OrdinalCLIP은 학습가능한 context token과 학습 가능한 rank embedding으로 이루어져 있습니다. learnable context token은 모든 rank에 대해 공유되고 context word를 modeling하는 데에 사용됩니다. large language model은 보통 완전히 number의 continuous한 특징을 학습하기 않기 때문에, 여러 base feature간의 interpolating에 의해 rank embedding을 학습하고 이를 통해 rank embedding의 연속적인(continuous 한) 특징을 명시적으로 modeling할 수 있습니다.
즉 이 논문의 main contribution은 다음과 같습니다.
1. ordinal regression을 위해 고정된 language model로부터 language prototype을 학습하는 새로운 paradigm 제시.
2. learnable rank embedding을 통해, CLIP의 text encoder로부터 langauge prior를 활용해 명시적으로 rank의 continuous한 특징을 modeling 가능.
3. 다양한 실험으로 제시한 paradigm의 효과를 증명.

Proposed Approach
Problem Statement
ordinal regression은 image가 주어지면 rank number나 continue value를 측정하는 것입니다. single neuron으로 값을 바로 regress할 수 있지만, 유명한 baseline들은 이를 classification task로 다루고 ordinal 특성을 사용할 수 있도록 추가적인 constraint를 이용합니다. 수학적으로, rank space를 R={r(j)|0<=j<C}로 두고, 여기서 r(j)는 rank category를 의미하고, C는 rank category의 수를 나타냅니다. 학습하는 동안 임의로 image의 batch X와 이와 관련된 label Y를 sampling하고, B는 batch size를 표현합니다. classification baseline에선 각 rank를 class number로 다룹니다.



sample x(i)에 대한 rank label이 r(j)로 가정한다면, l=j면 y(i,l)=1로 하고, 그게 아니면 y(i,l)=0으로 setting해서 one-hot label로 구성합니다. image는 우선 image encoder로 들어가 image feature f={f(0),f(1),...,f(B-1)}를 추출하고, 여기서 각각의 f(i) 는 image x(i)의 추출된 feature입니다. d는 feature dimension을 의미합니다. 그리고 image feature들은 parameter의 set W와 b로 이루어진 linear layer로 보내집니다.l(i,j)=w(j)f(i)+b(j), 여기서 l(i,j)는 image x(i)의 rank r(j)에 대해 예측된 logit입니다. 그리고 model은 cross-entropy loss로 최적화됩니다.
여기서 W는 Cxd로 이루어진 W=[w(0),w(1),...,w(C-1)] 형태이고, b는 dimension이 C인 b=[b(0),b(1),...,b(C-1)]입니다.
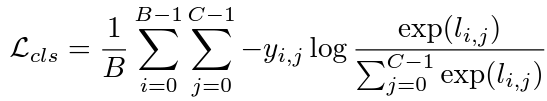
기존의 많은 방법은 classification formulation을 기반으로 많이 발전되어 왔습니다 (ex) label distribution, mean-variance loss). 그러나 이 방법들은 단순히 각 rank를 숫자로 다루고 training data로부터 나온 rank 개념을 주로 학습하기 때문에 overfitting 문제가 일어나기 쉽고 결국 성능 저하의 원인이 됩니다. 이 논문에선, language-powered paradigm을 제시하고, 이를 통해 이런 issue들을 다룰 수 있도록 language로부터 rank 개념을 학습합니다.
Language Prototypes
natural language에는 충분한 prior knowledge가 존재합니다. ordinality를 보존하기 위해서, 학습된 rank category를 이에 대한 language 개념과 연결짓고자 합니다. language를 충분히 활용하기 위해서, CLIP의 text encoder를 language model로 활용합니다. CLIP은 vision-language pre-training framework를 따르고 image-text pair로부터 representation을 학습해, 결합된 형태의 vision-language latent space를 얻게 됩니다. CLIP model은 downstream task에서 좋은 성능을 보였기 때문에, CLIP-powered text encoder를 활용합니다.
ordinal regression task를 image-language matching problem으로 재정의 하면서, text encoder와 image encoder로 구성합니다. text encoder는 고정된 CLIP language model을 통해 language feature를 뽑아내는 데에 사용됩니다. text encoder의 parameter는 고정되어 있기 때문에, text는 잘 학습된 language latent space에 mapping되고, 이는 풍부한 정보를 가진 language prior를 encoding합니다.
text encoder에 있는 language prior를 잘 활용하기 위해 rank category를 단어로 취급합니다. 그 다음 rank categoy에 대한 단어의 set을 얻습니다 {[r0],[r1],[r2],,,[rc-1]}. 각 rank에 대해 language embedding을 얻기 위해, 각 rank에 대한 sentence를 구성하고 text encoder에 이 전체 sentence를 보냅니다. 예를 들어, 특정 rank [rj]에 대한 sentence로 "a person at the age of [rj]"를 구성했다면, 이 문장의 각 단어는 512-D word embedding vector로 mapping됩니다. 모든 word embedding은 text embedding을 얻기 위해 text encoder로 들어갑니다. mapping된 embedding은 이제 각각에 해당하는 rank category의 prototype으로 다뤄집니다. 이 방식으로, 각 rank category는 language latent space에서 text embedding과 mapping됩니다. 이런 prototype은 잘 학습된 language manifold에 있고 language concept를 잘 encoding하기 때문에, 이를 language prototype으로 명명합니다. 앞으로 p(i)는 rank r(i)의 language prototype이고 d는 feature dimension을 의미합니다.
input image는 image encoder에 들어가 image feature를 추출하는 과정을 거칩니다. image encoder로 아무 유명한 vision backbone 사용 가능합니다. text encoder의 parameter는 고정되어 있기 때문에, 전체 image encoder가 language latent space의 image feature에 align하도록 학습합니다. image의 batch X에 대해, l2 normalize된 image feature를 I로 지정합니다. image-language matching framework로, inner product를 통해 두 modality간의 similarity 점수를 계산하고 similarity matrix A=[a(i,j)]를 얻습니다.

이 때 network를 optimize하기 위해 image-text contrastive loss를 사용하고, 이는 CLIP에서 사용되는 image-to-text loss와 text-to-image loss로 이루어져있습니다.
image-to-text loss에 대해, softmax layer를 사용해 matrix A=[a(i,j)]의 row를 normalize해서 matrix A'=[a'(i,j)]를 얻습니다.

여기서 T는 temperature parameter입니다. 우리는 KL divergence를 사용해서 matrix A'와 label Y간의 discrepancy를 최소화합니다.
text-to-image loss에선, zero 혹은 multiple hit이 있을 겁니다. 그렇기 때문에 Y의 non-zero column을 normalizing해서 label matrix Y''로 만듭니다. 그리고 column-normalized matrix A''=[a''(i,j)]를 얻습니다.
그리고 matrix A''와 label matrix Y''간의 discrepancy를 minimize하기 위해 KL divergence를 사용합니다. 결국 다음과 같은 image-text contrastive loss를 얻게 됩니다.
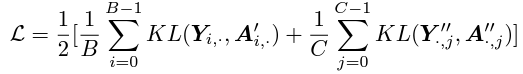
Learning Rank Prompts
prompt라 불리는 text input에 따라 성능은 매우 다르게 나타날 것입니다. prompt context를 설계하는 대신, prompt context를 다뤄주는 m개의 word embedding을 바로 학습합니다. 그리고 이는 rank의 word embedding과 concat되고 text encoder로 보내집니다.
model의 ordinality를 더 강화시키고 성능을 높이기 위해, language latent space에서 language prototype의 순서를 유지할 수 있도록 rank embedding을 학습합니다. CLIP를 regression에 바로 적용할 수 없는 이유는 rank label로부터 얻은 human-build prompt는 ordinality를 얻을 수 없고, 이는 저하된 성능을 야기합니다. word embedding space에서 arithmetric property에 영감을 받아, language prototype의 순서를 보존할 수 있는 rank embedding의 순서를 유지하고자 했습니다. 이 ordinality를 continuity의 자연스러운 결과로 간주할 수 있습니다.
interpolation을 통해 base rank embedding의 set으로부터 ordinal rank embedding을 반영합니다. base rank embedding의 set R'=[r'0,r'1,...,r'c'-1]가 있다고 했을 때, c'는 embedding의 수를 의미하고, R'은 512xc'으로 이루어집니다. 이 때 C'는 C와 비교했을 때 매우 작은 숫자입니다. 이후 j번째 rank embedding은 다음처럼 얻을 수 있습니다.

여기서 w'는 interpolation weight이 됩니다.

여기서 I(.)는 interpolation function이고, |.|는 절댓값을 의미합니다. 크게 2가지의 interpolation 방법을 사용합니다.
linear interpolation과 inverse-interpolation이고 각각의 식은 다음과 같습니다.


ordinalCLIP의 rank prompt에 대한 자세한 내용은 아래에 있는 figure를 참고하시면 됩니다.

위의 그림은 OrdinalCLIP의 framework입니다. rank category를 text로 다루고 language prior를 활용하기 위해 language model을 사용합니다. 각 rank에 대해, word embedding과 학습가능한 prompt context를 concat합니다. 그리고 이 concat된 것은 이에 해당하는 language prototype을 뽑아내ㅔ기 위해 language model로 들어갑니다. language prototype의 ordinal한 특성을 보존하기 위해, 여러 base rank embedding로부터 interpolate된 ordinal한 rank embedding을 설계합니다. 이렇게 생성된 ordinal rank embedding의 연속적인 특성이 language model을 통해 language prototype으로 propagation되어, language prototype도 ordinal property를 가지게 됩니다.
ordinalCLIP에서 학습을 하는 동안은 language concept을 이용해 huge language model을 사용합니다. 그러나 testing 할 때엔 학습된 language prototype만 사용할 수 있습니다. 그렇기 때문에 linear head 방식과 비교했을 때 추가적인 computational이나 storage overhead가 필요하지 않습니다. (훈련과정에서는 각 rank에 해당하는 language prototype을 생성하기 위해 language model을 적극 활용해야 하기 때문. 훈련 중 생성된 language prototype은 고정된 값이므로 이를 저장해두고 테스트 시 바로 활용 가능)
Experiments
1. Age Estimation
Datasets
facial age estimation의 task는 얼굴 이미지를 보고 나이를 예측하는 것입니다. dataset으론 자주 사용되는 MORPH2와 Adience dataset을 활용했습니다. Morph는 55134의 이미지와 13618명으로 이루어집니다. 각 image는 16살부터 77살까지 age 값이 labeling되어 있습니다.
2. Image Aesthetics Assessment
Dataset
image aesthetic dataset은 4개의 category로 이루어진 13929 Flickr photo로 이루어져 있습니다. (nature, animal, urban, poeple). 5개의 absolute rating scale이 aesthetic quality(미적품질)을 평가하도록 사용됩니다. ("unacceptable(불합격)","flawed(결합이 있는)","ordinary(보통)","professional(전문적)","exceptional(뛰어난)").
각 image는 최소 5명의 examiner로 판단되고 ground truth로 median rank를 사용합니다. 전체 dataset은 3개의 non-overlapped subset으로 임의로 분리됩니다. 5-fold cross-validation 사용됐습니다.
Results

위 테이블은 image aesthetic에 대한 quantitative 결과입니다. accuracy와 MAE가 평가기준입니다.
확실히 language prior가 model이 더 좋은 성능을 내도록 도와주는데, zero-shot CLIP을 보면 ordinal concept을 잘 구분하기 어려워하는 것을 볼 수 있습니다.
3. Historical Image Dating
Dataset
이 dataset은 이미지를 보고 이미지가 속한 decade를 예측하는 작업입니다. 총 1930년대부터 1970년대까지 5개의 10년대에 해당하는 이미지가 포함됩니다. 그리고 여기선 10-fold cross-validation을 진행합니다. score metric은 MAE와 accuracy입니다. 이 이미지는 10년대 category prediction을 다루기 때문에, rank prediction에 적합한 dataset입니다. 이 dataset에서 각 image는 특정 decade에 속하고, ordinalCLIP은 이를 rank value로 예측할 수 있습니다.
Discussions and Conclusions
OrdinalCLIP은 ordinal regression에 대한 일반적인 방법입니다. 이는 age estimation을 포함해 다양한 vision task에 적용 가능합니다. 기존의 이런 task들은 주로 training data에서 rank concept을 학습하기 때문에 overfitting 문제가 발생하기 쉽고, latent space에서 rank concept을 보존하기가 어렵습니다. 그렇기 때문에 ordinalCLIP은 각 rank category를 CLIP의 text encoder에서 추출된 language concept과 연결합니다. 이를 통해 각 rank를 language prototype으로 mapping합니다. 이 방법은 language의 prior를 활용하는데, 이것이 model이 rank를 예측하는 데 많은 도움을 줍니다. 그리고 ordicalCLIP은 rank embedding을 명시적으로 학습할 수 있도록 learnable rank prompt를 제안합니다.