Abstract
사람은 원하는 만큼 image contents를 거친 수준부터 정밀한 수준까지 묘사할 수 있습니다. 그러나 대부분의 image captioning model들은 사용자의 의도에 따른 다양한 설명들을 생성할 수 없는 'intention-agnostic'입니다. 논문에선 fine-grained level에서 사용자의 의도를 표현하고 어떤 description을 얼마나 생성할지 조절하는 'Abstract Scene Graph(ASG)'를 제안했습니다. ASG는 구체적인 semantic label없이 image에 근거를 둔 3가지 타입의 abstract node로 구성되어 있는 directed graph입니다. 그렇기 때문에 직접적으로도 자동적으로도 얻기 쉽습니다.
ASG를 이용해, novel ASG2Caption model을 제안했고, 이는 사용자의 의도와 graph의 의미를 인식하고, graph structure에 따라 원하는 caption을 생성합니다. (image, graph -> caption) VisualGenome, MSCOCO dataset 둘 다에서 신중히 설계된 baseline보다 더 ASG 조건에 따라 더 좋은 controllability를 얻을 수 있었습니다. 또한 control signal로 다양한 ASG를 자동적으로 sampling함으로써 caption diversity도 향상시킬 수 있었습니다.
Introduction
image captioning은 object recognition, scene classification, attributes, relationship detection과 같은 computer vision task
들을 수행할 뿐만 아니라 동시에 이 내용들을 문장으로 요약해야 하기 때문에 복잡한 문제입니다. 대부분의 image captioning model은 intention에 무관하게 작용되고 유저가 어떤 content에 관심이 있고, description을 얼마나 detail하게 할건지에 대해 신경쓰지 않은 채로 image description을 생성합니다. 그치만 인간은 원하는 만큼 from coarse to fine detail을 조절할 수 있습니다.

위의 그림을 보면, 우리가 원하는 만큼 더 차별적인 detail을 사할 수 있습니다. 그러나 현재 시스템들은 이런 유저의 의도를 인식하기 어렵습니다. 설상가상으로, 이러한 passive caption generation은 다양한 caption을 생성하는 diversity를 막고 mediocre description을 생성하는 경향이 있습니다. 높은 정확도를 보여줌에도 불구하고, 이런 description들은 보통 빈번하고 흔한 descriptive pattern을 포착하고 image에서 다른 면을 인식하거나 그래서 더 다양한 description을 생성할 수 있도록 하는 그런 신선한 image understanding을 표현할 수 없게 됩니다.
이전 연구들은 이런 한계를 다루기 위해 직접적으로 image captioning process를 조절할 수 있도록 노력해왔습니다. 한 예시로 factual, romantic, humorous 스타일과 같은 image description의 expressive 스타일을 조절하는 것에 초점을 맞춘 연구가 있었습니다. 또 다른 하나는 다른 image region, object, part-of-speech tagging과 같은 description content를 조절해서 image에서 사용자가 흥미있는 content를 묘사할 수 있도록 하는 것이 있습니다. 그러나 이런 연구들은 단순히 one-hot label이나 image region의 set들과 같은 coarse-grained control signal만을 다룰 수 있고, fine-grained level에서 사용자가 원하는 만큼의 control을 할 수 없습니다. 예를 들어 여러 단계의 detail에서 다양한 object을 묘사하거나 그들간의 관계를 나타내는 것을 어렵습니다.
이 논문에선, more fine-grained control signal인 Abstract Scene Graph (ASG)를 제시했고, 이는 조절이 가능한 image captiong generation을 위해 다른 intention을 표현합니다.
위의 figure에서 볼 수 있듯이 ASG는 image을 기반으로 abstract node의 3가지 type (object, attribute, relationship) 으로 구성되어 있고 각 node에 구체적은 semantic label은 따로 필요하지 않습니다. 그렇기 때문에, 이런 graph 구조는 semantic recognition이 필요하지 않기 때문에 직접적으로도 자동적으로도 쉽게 얻을 수 있습니다. 더 중요한 건, ASG는 무엇을 묘사하고 얼마나 detail할지 사용자의 fine-grained 의도를 반영할 수 있습니다.
ASG를 고려해서 caption을 생성하기 위해, enconder-decoder framework에 기반한 ASG2Caption model을 제안했고 이는 ASG 제어 caption generation의 3가지 과제를 해결할 수 있습니다.
첫번째로, ASG는 어떠한 semantic label없이 추상적인 scene layout으로 이루어져 있기 때문에, graph에서 intention과 semantic을 모두 포착해야 합니다. 이를 위해 'role-aware graph encoder'를 제시했고 이는 node의 세밀한 intention 역할을 나누고 semantic representation을 향상시키기 위해 graph context로 각 node를 향상시킵니다.
두번째로, ASG는 다른 node들을 통해 어떤 content를 묘사할지 조절할 뿐만 아니라, node가 어떻게 연결됐냐에 따라 descriptive order도 암묵적으로 결정합니다. 그렇기 때문에 여기서 제시한 decoder는 node의 content와 structure 모두 고려해 attention을 얻고, 이를 통해 graph flow order에 따라 원하는 content를 생성합니다.
마지막으로, 빠뜨리거나 중복없이 ASG에 나와있는 모든 정보들을 다뤄야 합니다. 이를 위해 model은 decoding하는 동안 graph access status를 추적하기 위해 계속 graph representation을 update합니다.
ASG annotation에 대해 다룰 수 있는 dataset이 없기 때문에, 자주 사용되는 2개의 image captioning dataset (VisualGenome, MSCOCO)을 이용해 자동으로 ASG를 생성했습니다. 기존의 baseline보다 설계된 ASG가 주어졌을 때 더 좋은 controllability를 보였고, image의 다양한 측면을 묘사하는 것도 자동으로 sample된 ASG를 사용했을 때 더 다양한 caption을 생성할 수 있는 것을 보였습니다.
이 논문의 contribution은 크게 3가지입니다.
1. ASG를 통한 fine-grained control이 가능한 image caption generation (detail의 level을 조절 가능)
2. 자동으로 abstract graph node를 인식하고 의도된 content와 순서를 고려한 caption을 생성할 수 있는 ASG2Caption model (role-aware graph encoder & language decoder for graphs)
3. designated ASG가 주어졌을 때 SOTA controllability 달성
Related Work
Image Captioning
대부분의 image captioning은 neural encoder-decoder 기반으로 발전되었습니다. Show-Tell model은 image를 fixed-length vector로 encoder하기 위해 CNN을 사용하고, 단어를 순차적으로 생성하기 위해 RNN을 사용했습니다. 더 세밀한 detail을 얻기 위해 'attentive image captioning model'은 생성 과정에서 관련된 image part를 기반으로 동적으로 ground word를 생성했습니다. sequntial training 과정에서 exposure bias와 metric mismatching을 줄이기 위해, reinforcement learning을 사용해 non-differentiable metrics로 최적화하는 방식이 있습니다. 개념들에 대한 더 구조화된 표현을 갖는 scene graph가 image captioning에 적용되며 object와 그들간의 관계를 탐지하는 데에 사용되었습니다. 이 논문에선, fully detected scene graph를 사용하는 대신, 사용자가 원하는 다양한 image caption을 생성하기 위한 control signal로써 abstract scene graph를 사용했습니다. ASG는 fine-grained level에서 captioning을 조절하는 데에 다루기 쉽고, fully detected scene graph보다 더 자동으로 얻기도 쉽습니다.
Controllable Image Caption Generation
controllbable text generation은 원하는 control signal (sentiment, style, semantic)등을 기반으로 문장을 생성하는 것을 목표로 합니다. 이런 generation은 더 상호적이고 해석 가능하며 다양한 문장을 생성할 수 있습니다. image captioning을 조절하는 데에 크게 2개의 group (style control, content control)으로 분류할 수 있습니다.
style control은 말그대로 하나의 image에 대해 다양한 style로 묘사하는 것입니다. 여기서 가장 challenge는 training 할 때 다양한 style로 이루어진 text pair들이 부족하다는 점입니다. 이를 해결 하기 위해 최근 연구는 semantic content에서 style code를 분리해 style이 쌍으로 이루어지지 않아도 학습이 가능하도록 합니다.
e.g., Stylenet : Generating attractive visual captions with styles, Mscap:Multi-style image captioning with unpaired stylized text, Semstyle:Learning to generate stylised image captions using unaligned text
content control은 다른 region이나 obejct와 같은 image에서 다른 측면을 포착해서 caption을 생성하도록 합니다. 이 경우 더 holistic한 visual understanding을 할 수 있습니다. "Densecap: Fully convolutional localization networks for dense captioning." 에선 image에서 다양한 region을 탐지하고 묘사하는 dense captioning task가 고안되었습니다.
"Intention oriented image captions with guiding objects"에선 human concerned object를 반영하도록 모델을 제한했습니다.
이런 연구들이 진행되었지만 이는 더 fine-grained level에서 caption generation을 조절할 수 없었습니다. 얼마나 많은 그리고 해당 attribute이 사용되어야 하는지, 혹은 object나 관련된 relationship이 포함되어야 하는지 그리고 description order는 어떤지 등에 대해선 조절할 수 없다는 것입니다. 이 논문에선 fine-grained ASG를 사용해 고안된 object, attribute, relationship의 구조를 조절하고 동시에 다른 intention들을 반영할 수 있는 더 다양한 caption을 생성할 수 있도록 합니다.
Abstract Scene Graph
fine-grained level에서 user intention을 표현하기 위해, ASG(Abstract Scene Graph)를 control signal로 사용합니다. image I에 대한 ASG는 g=(v,e)로 표현되고 v와 e는 각각 node와 edge의 set을 의미합니다.
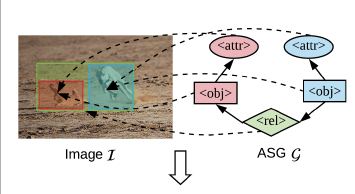
node는 각 node의 intention role에 따라 3가지 type으로 분류될 수 있습니다. object node o, attribute node a, relationship node r.
user intention이 g에 반영되는 방법은 아래와 같습니다.
- user가 실제 image I에 bounding box와 같이 존재하는 관심있는 object o(i)를 g에 추가합니다.
- user가 o(i)에 대해 더 구체적인 detail을 원하면, g에 attribute node a(i,l)을 추가하고 o(i)에서 a(i,l)로 가는 directed edge를 할당합니다. 하나의 o(i)에 대해 여러 attribute a(i,l)가 있을 수 있기 때문에 |l|은 관련된 attribute의 수를 의미합니다.
- user가 subject (i)와 object o(j)간의 relationship을 묘사하고 싶으면 relationship node r(i,j)를 g에 추가하고 o(i)->r(i,j)와 r(i,j)->o(j)에 directed edge를 각각 할당합니다.
물론 user를 통해 g를 얻을 수 있지만, 기ㅣ존의 object proposal network를 통해 ASG를 자동으로 생성할 수 있고 선택적으로 relationship classifier를 적용해서 두 object간의 어떤 관계가 있는지 알아낼 수 도 있습니다.
이 때, ASG는 semantic label없이 단순한 graph layout이기 때문에, scene graph를 기반으로 한 image captioning model에선 label을 가진 scene graph를 제공하기 위해 잘 훈련된 detector가 필요했지만, 이 model에선 직접적으로 object/attribute/relationship detector를 훈련할 필요가 없습니다.
자동으로 ASG를 생성하는 상세 설명은 supplementary에 포함되어 있습니다. 다양한 ASG는 image에서 다른 측면을 포착해 추출될 수 있고 결국 다양한 caption을 생성할 수 있게 됩니다.
ASG2Caption model
image I와 고안된 ASG g가 주어졌을 때, 우리의 목표는 user의 intention을 만족한 g에 정밀하게 맞춘 sentence y={y1,...,yt}를 생성하는 것입니다.

Role--aware Graph Encoder
encoder는 image I에 기초를 둔 ASG g를 node embedding의 set인 X={x1,...,x|v|}로 바꿉니다. 우선 x(i)는 visual appearance 뿐만 아니라 intention role로 반영해야 합니다. 특히 여기서 object와 연결된 attribute node들은 같은 region에 위치해 있기 때문에 이 둘을 구분하는 것은 중요한 일입니다. 두번째로 node들은 각자 고립되어 있지 않고, 이웃노드들과의 contextual information을 고려하면 node의 semantic meaning을 더 잘 알 수 있습니다. 따라서 node intention을 잘 구분할 수 있는 role-aware node embedding을 사용하고 contextual encoding을 위해 MR-GCN(multi-relational graph convolutional network)를 사용합니다.
Role-aware Node Embedding
g에 i번째 node가 있을 때, 우선 일치하는 visual feature v(i)로 초기화시킵니다. object node의 feature는 image에서 위치한 bounding box로 부터 추출됩니다. attribute node의 feature도 object node와 동일하고, relationship node의 feature는 연관된 두 object의 union bounding box로부터 추출됩니다. 이 때, 이런 visual feature(시각적 정보)만으로는 g에 있는 각 node가 어떤 role을 하는지 구별하기 어렵기 때문에, 각 node에 역할을 인식할 수 있는 추가 정보를 더해 node embedding을 개선합니다. 이를 통해 node의 role과 시각적 정보를 결합해 더 정교한 representation을 얻을 수 있습니다.

여기서 W(r)은 role embedding matrix이고, d는 featuree dimension, W(r)[k]는 W(r)의 k번째 row를 의미하고, pos[i]는 같은 object에 연결되어 있는 여러 attribute node의 순서를 구분하기 위핸 positional embedding입니다.
Multi-relational Graph Convolutional Network
ASG의 edge는 단방향이지만, 연결된 node간의 영향은 상호적입니다. 또한 node들 간의 여러 type이 있기 때문에 한 type의 node에서 다른 type의 node로 message를 passing하는 방식은 그 반대 방향의 message passing과 방식이 다를 수 있습니다. 그러므로 원래의 ASG를 확장해 서로 다른 bidirectional(양방향) edge를 추가해 다양한 relation이 있는 multi-relational graph g(m)={v,e,r}를 생성하고, 이를 통해 contextual encoding을 할 수 있습니다. 이렇게 추가된 edge들은 총 6가지의 type으로 나뉠 수 있습니다. (object->attribute, attribute->object, subject->relationship, relationship->subject, relationship->object, object->relationship) mulil-relationalg graph인 g(m)에 대한 graph context를 encode하기 위해 MR-GCN을 사용합니다.

여기서 N은 어떤 relation r에 해당하는 i번째 node의 neighbor를 의미하고, sigma는 ReLU activation function, W(l)은 l번째 MR-GCN layer에서 학습되는 parameter를 의미합니다. 하나의 layer를 사용하면 각 node에 대해 직접적인 이웃 노드로부터의 context를 가져오게 되지만, 여러 layer를 쌓게 된다면 graph에서 더 넓은 문맥에서 encoder를 할 수 있습니다. L개의 layer를 쌓고 마지막 L번째 layer의 output이 우리의 마지막 node embedding X로 사용됩니다. global graph embedding으로 X의 평균을 취해서 얻을 수 있습니다. (모든 node embedding vector에 대한 평균). 그리고 이런 gloabal graph embedding을 global image representation과 합쳐 global encoder feature v로 사용됩니다.
Language Decoder for Graphs
decoder는 encoding된 g를 image caption으로 변형하는 역할을 합니다. unrelated vector의 set을 사용하는 이전 연구들과 달리 현재 우리가 구한 node embedding X는 g로부터 구조화된 connection을 포함하기 때문에, 무시할 수 없는 사용자로 고안된 order를 반영합니다. 나아가, 사용자의 intention을 완전히 만족하기 위해 g에서 빠뜨리거나 중복없이 g에 있는 모든 node를 표현하는 것이 중요합니다. 이전의 attention 방법들은 attended vector가 얼마나 자주 사용되었는지를 충분히 고려하지 않았습니다. graph의 sentence quality를 향상시키기 위해, graph에 대한 language decoder를 사용했고 이는 graph semantic 과 structure를 모두 고려하는 graph-based attention mechanism과 무엇이 설명되고 안되었는지에 대한 기록을 갖는 graph updating mechanism으로 이루어져 있습니다.
Overview of the Decoder (다시보기)
decoder는 2-layer LSTM 구조를 사용하고 이는 attention LSTM과 language LSTM에 해당합니다.
attention LSTM은 global encoded embedding v, 이전 word embedding w(t-1)와 language LSTM h(t-1)로부터 나온 이전 output을 input으로 받고 attentive query h(t)(a)를 계산합니다.

t-step에서의 node embedding은 X(t)로 정의하고, X(1)은 encoder의 output X가 됩니다. 여기서 계산된 h는 graph-based attention mechanism을 통해 X(t)로부터 context vector z(t)를 뽑아내는 데에 사용됩니다.
language LSTM은 z(t)와 h(t)(a)가 들어가서 단어를 순차적으로 생성합니다.
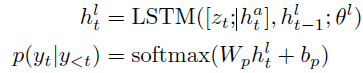
이전 단어들이 주어졌을 때 다음 단어가 나올 확률로 값이 나오게 됩니다.
Graph-based Attention Mechanism
semantic content와 graph structure를 모두 다루기 위해, 2가지 type의 attention을 결합시킵니다. (graph content attention + graph flow attention)
graph content attention은 node embedding X(t)와 qury h(t)(a)간의 semantic relevancy를 고려해 attention score vector a(t)(c)를 계산합니다.

W(xc),W(hc),w(c)는 content attention의 parameter이고 심플함을 위해 bias term은 생략했다고 합니다. 여기선 node간의 connection이 고려되지 않기 때문에, content attention은 g에서 어떤 node에서 멀리있는 다른 node가는 teleport(순간이동)과 비슷하다고 볼 수 있습니다. 여기서 teleport와 비슷하다고 하는 것은, decoding의 다양한 time step에서 매번 새로운 query vector를 생성하게 되는데 현재의 query vector에 따라 거리와 상관없이 graph에 있는 어느 node든지 주목할 수 있으며, 이 과정에서 node 간 물리적 distance가 connection을 무시한다는 것을 의미합니다.
그러나 ASG의 구조는 caption generation에서 user가 의도한 order를 암묵적으로 반영하게 됩니다. 만약 현재 주목받은 node가 relationship node라면, 다음으로 접근될 node는 graph flow에 따라 이어지는 object node가 되는 것이 그럴 듯 합니다. 그렇기 때문에, 이런 graph structure를 포착하기 위해 graph flow attention를 고안했습니다. flow graph g(f)는 3가지 측면에서 original ASG와 다릅니다.
1. start symbol S가 정해져야 함
2. object node와 attribute node은 bidirectional connection이다. 즉 이말은 하나의 node가 다른 하나의 node에 영향을 주는 단방향의 흐름이 아닌 서로가 서로에게 영향을 줄 수 있다는 점입니다. 그리고 이 둘의 방향 순서는 강제적(compulsive)이지 않고 문장의 자연스러움과 유창성에 의해 결정되어야 합니다. e.g., "black cat"도 맞지만 "cat is black"도 맞기 때문입니다.
3. 어떤 node에 output edge가 없다면 self-loop edge를 만들어서, graph의 attention이 사라지지 않도록 보장하기
M(f)가 flow graph g(f)의 adjacent matrix라고 해봅시다. 이 때 i번째 row는 i번째 node의 정규화된 in-degree를 나타냅니다. graph flow attention은 이전 decoding step a(t-1)의 attention score vector를 3가지 방식으로 전달합니다.
1. 같은 node에선 유지 (한 node에 대해 여러 단어를 표현 가능)
2. 1 step 가기 (relationship node에서 object node로 가기)
3. 2 step 가기 (relationship node에서 attribute node로 가기)

마지막 flow attention은 3개의 flow score를 dynamic gate로 조절한 soft interpolation입니다.
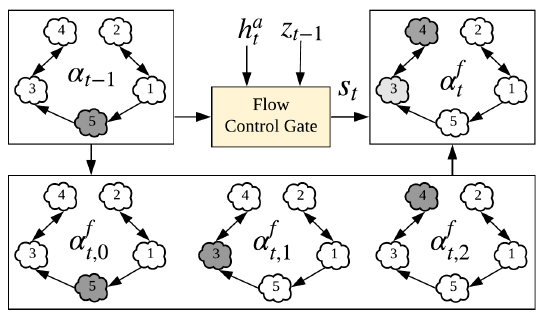
위의 그림은 다음 단어를 생성할 때 관련있는 node를 선택하기 위해 graph flow order를 사용하는 graph flow attention입니다.
graph-based attention은 동적으로 graph content attention a(t)(c)와 graph flow attention a(t)(f)를 learnable parameter를 통해 합칩니다. (w(g),W(gh),W(gz))

t번째 step에서의 단어 예측을 위한 context vector z(t)는 graph node feature의 weighted sum이 됩니다.
Graph Updating Mechanism
각 decoding step에서 다른 node에 대해 접근 상태에 대한 기록을 저장하기 위해 graph representation을 update합니다. attention score a(t)는 각 node의 접근된 'intensity'를 나타내서 강하게 집중된 node는 더 많이 update되도록 합니다. 그러나 "the"나 "of"처럼 눈에 보이지 않는 단어들을 생성할 땐, graph node가 이미 접근이 되어도, 시각적인 정보와 직접적인 관련이 없기 때문에, 이런 단어를 생성할 때엔 graph node의 상태를 update할 필요가 없습니다. 그렇기 때문에 시각적 정보를 포함하는 단어를 생성할 때만 graph node의 embedding을 update해야 하며, 문법적 역할을 하는 non-visual word를 생성할 때는 node를 update하지 않는 것이 중요합니다. 이를 위해 visual sentinel get를 사용해 attention intensity를 상황에 맞게 조절하도록 합니다.

f(vs)는 theta를 parameter로 갖는 fully connected netowkr이고 이는 이번에 집중된 node가 생성된 단어와 관련있는지를 나타내도록 scala값을 출력합니다.
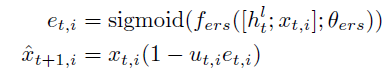

Training and Inference
ASG2Caption model 학습시키기 위해 standard cross entropy loss 사용.
single pair (I,G,y) 에 대한 loss는 다음과 같습니다.

학습이 되면 모델은 image와 설계된 ASG가 주어졌을 때 조절가능한 image caption을 생성할 수 있습니다.
Experiments
Datasets
2개의 image captioning dataset 이용해서 triplet 만들기. (image I, ASG g, caption y)
[VisualGenome] : object annotation과 dense regions description(bounding box로 구분된 region에 대한 설명) 존재. caption과 region에 맞는 ASG를 얻기 위해 groundtruth region caption을 scene graph로 parse하기 위해 'Stanford sentence scene graph parser' 사용. 그 다음 object를 parsed된 scene graph에서 object들의 위치와 semantic label에 따라 object region으로 옮기기. object들을 align했으면, scene graph에서 모든 semantic label 제거, graph layout과 node type만 남김. '
[MSCOCO] : dataset는 120000 이상의 image를 갖고 각 image는 대략 5개의 description을 갖고 있음. VisualGenome에서 한 것처럼 ASG 얻기 위해 똑같이 진행. 그리고 "Karpathy" split setting 적용. VisualGenome보다 MSCPCP가 더 복잡함.
Experimental Settings
Evaluation Metrics
2가지 측면에서 caption quality 평가 가능 (controllability & diversity)
[controllability] : groundtruth image caption으로 align된 ASG를 control signal로 사용. 생성된 caption은 5가지 automatic metric를 통해 groundtruth를 기준으로 평가합니다. (BLEU,METEOR,ROUGE,CIDEr,SPICE). 일반적으로 이런 score들은 semantic recognition이 일치하고 문장 구조가 ASG보다 더 잘 부합하면 높은 점수를 얻습니다. SPICE를 기반으로 한 Graph Structure metric G는 순전히 구조가 ASG에 일치하는지만 확인합니다. 이는 (o),(o,a),(o,r,o) 각각의 pair들에 대해 groundtruth caption과 비교했을 때의 빈도 차이를 측정합니다. 이렇게 측정된 차이가 낮을수록 model이 더 정확한 caption을 생성하고 있다는 것을 의미합니다.
[diversity] : 우선 각 model에 대해 같은 수만큼의 image caption을 뽑은 뒤, 2가지 metric을 사용해 뽑은 caption의 diversity를 평가합니다.
1) n-gram diversity (Div-n) : 자주 사용되는 metric으로, 5개의 best sampled caption이 있을 때 중복되지 않는 n-gram의 비율을 전체 단어의 갯수로 나누는 것입니다.
2) SelfCIDEr : 최근 연구된 metric으로 "semantic diversity"(의미론적 다양성)을 측정하기 위해 개발되었습니다. 이 metric은 CIDEr와 관련이 있고, 잠재 의미 분석(latent semantic analysis, LSA)을 기반으로 하고 있습니다. 의미론적 similarity를 분석하기 위해 caption들의 의미를 latent semantic space에서 분석합니다. 또한 SelfCIDERr는 CIDEr라는 기존의 text similarity 평가 지표를 개선해서 사용합니다. CIDEr 점수를 kernelisation하여, caption들 사이의 의미론적 다양성을 더 잘 평가할 수 있도록 확장합니다.
Evaluation on Controllability
기존의 baseline들을 2개의 그룹으로 나누어 비교했습니다.첫번째 그룹은 기존의 intention-agnostic image captioning model로 Show-Tell(ST)와 BottomUpTopDown(BUTD)가 포함됩니다. Show-Tell(ST)는 pre-trained된 Resnet101을 encoder로 사용해 global image representation을 추출하고 LSTM을 decoder로 사용합니다. BottomUpTopDown(BUTD)는 다른 단어를 생성할 때 관련있는 image region을 동적으로 attent하도록 합니다. 두번째 그룹은 기존의 방식에서 조금 더 확장해 ASG-controlled image captioning 방식으로 이루어져 있습니다. non-attentive model (C-ST)에 대해, original feature에 global graph embedding g를 합칩니다. attentive model (C-BUTD)에 대해 model이 탐지된 모든 image region에 집중하는게 아닌 ASG의 graph node에만 집중하도록 만듭니다.

결과를 보면, control signal ASG을 알고 있는 controllable baseline이 non-controllable baseline보다 성능이 좋아지는 것을 알 수 있습니다. 기존 baseline의 모델들은 object와 relationship에 비해 attribute을 생성하는데에 어려움을 겪고 있습니다. 이에 반대 이 논문에선 전체적인 caption quality와 graph structure에 대한 부합성도 잘 나옴을 알 수 있습니다. VisaulGenome와 MSCOCO에 대한 misalignment도 절반이상 줄였습니다.
Evaluation on Diversity
ASG-controlled image captioning은 추가적으로 다양한 ASG가 주어졌을 때 여러 level에서 image를 여러 측면으로 파악해 다양한 image description을 생성할 수 있습니다. 처음엔 image에 대해 자동으로 global ASG를 받고,, 그다음은 ASG로부터 sample subgraph를 얻습니다. 단순하게 하기 위해 임의로 연결된 subject-relationship-object node를 선택해 subgraph로 여기고 또 임의로 subject node와 object node에 하나의 attribute node를 추가합니다. VisualGenome dataset에서 다양한 caption을 만드는 dense image captioning approach를 비교합니다. 공평하게 하기 위해 ASG에서 뽑은 같은 region을 사용합니다. MSCOCO에선 image에 대한 global image description만 있기 때문에, BUTD model의 beam search를 이용해 baseline의 다양한 caption을 만듭니다.

'ours'가 만든 caption은 특히 semantic similarity에 집중한 SelfCider score에서 더 높은 점수를 받았습니다.
Conclusion
이 논문에선 원하는 image description을 생성하도록 하는 user intention을 적극적으로 고려한 controllable image caption generation을 제안햇습니다. 무엇을 얼마나 detail하게 묘사할지 조절할 수 있도록 하기 위해, ASG라 불리는 control signal을 제안했고 semantic label없이 image에서 위치한 3가지 타입의 abstract node로 이루어져 있습니다. ASG2Caption model은 ASG의 구조를 따를 수 있도록 role-aware graph encoder와 language decoder로 이루어져있습니다. 이 모델은 2가지 dataset에 대해 사용자가 원하는 ASG의 조건대로 조절이 가능한 controllability에서 SOTA 성능을 보였습니다. 또한 자동으로 sampling된 ASG가 주어졌을 때 caption의 diversity도 향상됨을 알 수 있습니다.



