https://openaccess.thecvf.com/content_cvpr_2017/html/Qi_PointNet_Deep_Learning_CVPR_2017_paper.html
CVPR 2017 Open Access Repository
Charles R. Qi, Hao Su, Kaichun Mo, Leonidas J. Guibas; Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 652-660 Point cloud is an important type of geometric data structure. Due to its irregular format, most r
openaccess.thecvf.com
3D point cloud generation에 대해 조사하다가 이에 기초가 되는 연구인 것 같아 알아보게 되었습니다.
point cloud는 비정형 데이터(irregular format)라 다루기 어려우며 이를 정형 데이터로 변형하더라도 sparse하기 때문에 다루기 어려운 점이 있었습니다. 그래서 point cloud를 deep learning architecture에 사용하기 전에 어떤 변형들을 거친 후 사용하는 방향으로 연구가 진행되었습니다. 그러나 이런 변형은 data의 부피가 불필요하게 커지게 되고, 이런 문제에 대해 경량화하는 방법도 있지만 결국 이런 경량화도 data의 자연적인 invariance를 흐리게 하는 단점이 있습니다.
그러나 이 논문에선 point cloud 자체를 input으로 사용해 deep learning에 적용하는 방법을 제시했습니다.
(For this reason we focus on a different input representation for 3D geometry using simply point clouds - and name our resulting deep nets PointNets)

point cloud는 mesh의 복잡성과 combinatorial irregularity(조합 불규칙성)를 방지할 수 있는 단순한 구조입니다. 하지만 point cloud은 point들의 set이기 때문에 각 point들에 대해 invariant하기 때문에 net computation에서 특정 symmetrization이 필요합니다.
PointNet은 point cloud를 input으로 받고 전체 input에 대한 class label이나 각 point에 대한 segment/part label을 output으로 도출합니다.
논문에선 initial stage에서 각 point가 identical하고 independent하게 진행되기 때문에 아주 단순한 구조라고 주장합니다. 각 point에 대한 기초 셋팅은 단순히 3개의 coordinate (x,y,z)가 됩니다. 추가적인 dimension은 normal과 local, global feature를 계산하며 추가할 수 있습니다.
"Key to approach"
: use single symmetric function, max pooling
network는 point cloud에서 관심있고 중요한 point들을 선택하도록 optimization function의 set를 학습하고 이런 선택들에 대한 이유를 encode합니다. 마지막 fully connected layer는 이렇게 학습된 optimal value를 global descriptor에 aggregate하고 이는 shape classification이나 shape segmentation을 위한 entire shape에 쓰이게 됩니다.
각 point들은 독립적으로 변형되기 때문에, input format은 rigid 혹은 affine transformation을 적용하기 쉽습니다. 그렇기 때문에 PointNet을 진행하기 전에 data를 표준화하도록 하는 data-dependent spatial transformer network를 추가할 수 있습니다. 이 과정이 성능을 향상시키는 데에 영향을 줬다고 합니다.
또한 저자는 이 network가 key point들로 이뤄진 sprase set을 구함으로써 input point cloud를 요약할 수 있고, 이는 대략적으로 visualziation에 따른 object의 'skeleton'이라고 볼 수 있다고 합니다.
PointNet이 input points의 작은 perturbation 뿐만 아니라 point insertion 같은 outlier나 deletion같은 missing data를 통한 corruption에도 robust한 이유에 대해 이론적인 분석도 설명합니다.
[contribution]
- 3D unorder point set에 적합한 deep net architecture 제시
- 3D shape classification, shape part segmentation, scene semantic parsing task에 사용 가능
- method의 stability와 efficiency에 대한 empirical, theoretical 분석 제시
- net에서 선택된 neuron으로 3D feature 계산 가능, performance에 대한 직관적인 설명 가능
(unordered set을 처리하는 문제는 여러 domain에서도 자주 발생하는 문제이기 때문에 이 method가 다른 domain에서도 적용될 수 있다고 합니다)
Related Works
Point Cloud Features
대부분 존재하는 point cloud에 대한 feature들은 specific task를 통해 수작업으로 만들었습니다. point feature는 자주 point의 특정 statistical한 특징을 encode하고 특정 transformation에 invariant하게 고안되었습니다. 이런 방법은 intrinsic 방법과 extrinsic 방법으로 분류됩니다. 또한 이런 feature들은 local feature와 global feature로 분류될 수도 있습니다. 특정 task에 대해선, optimal한 feature combination을 찾는게 쉽지 않습니다.
Deep Learning on 3D Data
3D data는 몇몇의 representation 방법이 있고, learning할 때 다양한 방법이 존재합니다.
Volumetric CNNs은 voxelized shape에 3D convolutional neural network를 적용한 선두주자라고 볼 수 있습니다. 이 방법의 문제는 data sparsity와 3D convolution의 computation cost로 인한 resolution에 제약이 있다는 점입니다. FPNN과 Vote3D는 이런 sparsity problem을 해결하기 위해 새로운 방법을 제안했지만, 여전히 sparse volume으로 작업을 진행하기 때문에 상당히 큰 point cloud를 처리하는 것은 어려운 문제입니다.
Multiview CNNs는 2D image에 3D point cloud나 shape을 render한 다음 classify를 하기 위해 2D conv net을 적용하고자 했습니다. 잘 설계된 image CNNs에선, 이런 방법들이 shape classification이나 retrieval task에서 좋은 성능을 냈습니다. 그렇지만 point classification, shape completion과 같은 3D task나 scene understanding 같은 task로 이 방법들을 확장하기엔 쉽지 않습니다.
Spectral CNNs는 비교적 최근에 제안된 방법으로 mesh에 spectral CNN을 사용합니다. 이 방법은 organic object와 같은 manifold mesh에 의해 제약이 있고, furniture와 같은 non-isometric shape에 확장하는 방법은 불분명합니다.
Feature-based DNNs는 처음으로 3D data를 vector로 변환했고, traditional shape feature를 뽑아 shape을 classify하기 위해 fully connected net을 사용했습니다. 이 논문의 저자는 이런 방법들이 feature를 뽑는 representation power에 한계가 있다고 주장했습니다.
Deep Learning on Unordered Sets
data 구조 관점에서 볼 때, point cloud는 vector의 unordered set이 됩니다. deep learning에서 대부분 sequence, image, volume 같이 regular input representation에 대해 집중 연구가 이뤄졌고, point set에 대해선 많이 다뤄지지 않았습니다.
어떤 연구(O. Vinyals, S. Bengio, and M. Kudlur. Order matters: Sequence to sequence for sets. arXiv preprint arXiv:1511.06391, 2015.)에선, 이런 문제를 파악하고 attention mechanism을 적용해 unorder input set을 사용하는 read-process-write network를 사용했고 결과적으로 이 network가 숫자를 분류할 수 있다고 주장했습니다. 그러나 이는 단지 generic set와 NLP application에 초점을 맞췄고, set에서 geometry 관점에 대한 역할은 고려하지 않았습니다.
Problem Statement
input으로 바로 unordered point set을 사용할 수 있는 deep learning framework를 고안했습니다. point cloud는 3D point 의 set {P|i=1,..,}로 표현할 수 있고, 각 point P는 (x,y,z) coordinate의 vector이고 여기에 추가적으로 color나 normal등의 feature channel을 가질 수 있습니다. 더 간단하고 명확히 하기 위해서, 논문에선 point의 channel로 (x,y,z) coordinate만 사용했다고 합니다.
object classification task에서, input point cloud는 바로 shape에서 sample되거나 , scene point cloud로부터 pre-segmented됩니다. pointNet에선 k candidate class에 각 class에 대한 k scores가 output으로 나옵니다.
semantic segmentation에선, input이 part region segmentation에 대한 single object가 될 수 있고, object region segmentation에 대한 3D scene으로부터의 sub-volume이 될 수 있습니다. model은 각 n point에 대해 각 m semantic sub-category에 대해 도출하기 때문에 output은 nxm score를 반환합니다.
Deep Learning on Point Sets
PointNet은 point set의 특징이 반영되었다고 합니다.
Properties of Point Sets
input은 Euclidean space의 point들의 subset이 됩니다. 총 3가지의 특성을 갖고 있습니다.
- Unordered
volumetric grid에서의 voxel array나 image에서 pixel array와 달리, point cloud는 특정 순서가 없는 point들의 set입니다. 즉, N개의 3D point set을 사용하는 network는 data를 주는 순서에서 input set의 N! permutation에 invariant 해야 합니다.
- Interaction among points
point들은 distance metric을 갖는 공간에서 생성됐습니다. 이는 point들이 고립되어 있지 않고, 주변 point들과 같이 의미있는 subset을 생성합니다. 그러므로, model은 주변 point들로부터 local structure를 포착할 수 있어야 하고, local structure들간의 combinatorial interaction도 포착해야 합니다.
- Invariance under transformations
geometric object에서, 학습된 point set의 representation은 특정 변형에 invariance해야 합니다. 예를 들어, 모든 point들을 한번에 회전하거나 translate해도 global point cloud의 category나 point들의 segmentation이 바뀌면 안됩니다.

PointNet Architecture
PointNet의 구조를 보면, classification network와 segmentation network는 구조의 상당 부분을 공유합니다.
PointNet엔 3개의 key module이 있습니다.
1. 모든 point들로부터의 정보들을 합치는 symmetric function으로서 사용되는 max pooling layer
2. local과 global information combination 구조
3. input point와 point feature 둘 다 정렬하는 two joint alignment networks
1. Symmetric Function for Unordered Input
input permutation에 invariant하기 위한 3가지 전략이 존재합니다.
1) input을 canonical order로 분류하기
2) input을 RNN을 훈련하는 sequence로 간주하기 (모든 종류의 permutation에 의해 training data가 augment되어야 함)
3) 각 point들로부터 얻은 정보를 통합하는 simple한 symmetric function 사용하기
여기서, symmetric function은 input으로 n개의 vector를 취하고, input 순서에 invariant한 새로운 vector를 출력합니다. 예를 들어, +와 * operator는 symmetric한 binary function입니다.
sorting이 간단한 해결 방법처럼 보이겠지만, 일반적으로 high dimensional space에서 point perturbation에 대해 stable한 ordering은 존재하지 않습니다. 예시를 들어보겠습니다. 어떤 ordering 전략이 존재하면, 이는 high-dimensional space와 1d real line 간의 bijection map으로 정의합니다. 보기엔 어렵지 않지만, point perturbation에서 대해 stable한 ordering인 것은, 이 map이 dimension이 줄어들어도 spatial proximity를 보장하는 것과 같고, task는 일반적으로 이런 경우를 만족할 수 없습니다. 그러므로, sorting 자체는 ordering issue을 완벽히 해결할 수도 없고, network가 ordering issue가 남아있는 상태로 input을 output으로 일관된 mapping을 학습하는 것도 어렵습니다.

실제로 바로 unsored input을 사용하는 것보단 성능이 잘 나오긴 하지만, sorted point set을 MLP에 넣는 것은 여전히 성능이 그닥 좋지 않습니다.
RNN을 사용하는 방법은 point set은 sequential signal로 여기고 랜덤하게 permuted sequence를 이용해 RNN을 training하면, RNN이 input order에 invariant하길 희망하는 방법입니다. 그러나 "OrderMatters"의 저자는 order는 실제로 중요하고 생략하면 안된다는 것을 보였습니다. RNN이 상대적으로 길이가 작을 때 input ordering sequence에 대해 robust하지만, 보통 point set 사이즈 만큼의 사이즈로 키우면 scale하기 어려워집니다.
결국 , 논문의 아이디어는 "set에서 변형된 element"를 symmetric function에 적용함으로써 point set으로 정의된 general function을 근사하는 것이 됩니다.
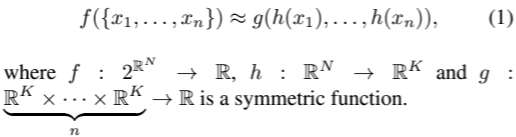
여기서 g가 symmetric function이 됩니다.
h : multi-layer perceptron network로 근사
g : single variable function & max pooling function의 composition으로 근사
h의 collection을 통해, set의 다양한 property를 포착하도록 여러개의 f를 학습할 수 있습니다.
2. Local and Global Information Aggregation
위에서 언급한 바에 의하면, output은 vector [f1,...,fk]를 형성하게 됩니다. 이는 input set의 global signature(기호)가 됩니다. 우리는 classification에 대해 쉽게 shape global feature에 대한 SVM이나 multi-layer perceptron classifier를 학습할 수 있습니다. 그러나, point segmentation은 local과 global knowledge의 조합이 필요합니다.
global point cloud feature vector를 계산한 뒤, 각 point feature에 계산한 global feature를 concat함으로써 point feature 별로 이 값을 반영할 수 있게 해줍니다. 그다음 이렇게 결합된 point feature를 기반으로 새로운 point 별 특징을 추출합니다. 이 때 point 별 특징은 local과 global 정보 모두를 알게 됩니다.
이렇게 수정된 network는 point별 quantity를 예측할 수 있고 이는 local geometry와 global semantic 모두를 고려하게 됩니다. 예를 들어 point별 normal을 정확히 예측할 수 있고, network가 주변 local neighborhood로부터 정보를 summarize 할 수 있다는 것을 입증합니다.
3. Joint Alignment Network
point cloud의 semantic labeling은 point cloud가 특정 geometric transformation(rigid transformation같은)이 되어도 invariant 해야합니다. 그렇기 때문에 point set에 의해 학습된 representation이 이런 변형에도 invariant하길 기대합니다. 자연스러운 방법은 feature extraction을 하기 전에 모든 input set을 canonical space로 정렬하는 것입니다. 논문에선 새로운 layer나 alias를 사용하지 않고 단순히 mini-network를 사용해 affine transformation matrix를 예측하고 바로 이 transformation을 input point의 coordinate에 적용합니다. mini-network 자체가 big network와 비슷하고 point에 독립적인 feature extraction, max pooling 과 fully connected layer의 basic module로 구성됩니다.
이 아이디어는 feature space의 정렬로 확장될 수도 있습니다. 또한 point feature에 다른 alignment network를 삽입할 수 있고 feature transformation matrix를 예측해 다양한 input point cloud로부터의 feature를 정렬할 수 있습니다.
그러나, feature space에서의 transformation matrix는 spatial transformation matrix보다 훨씬 큰 차원을 갖기 때문에 optimization하는 데에 어려움이 있어 이를 해결하기 위해 softmax training loss에 regularization term을 추가합니다. feature transformation matrix가 orthogonal matrix에 가까워지도록 제한합니다.
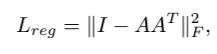
A는 mini-network에 의해 예측된 feature alignment matrix입니다. orthogonal matrix에 가까워지게 하도록 하는 이유는, orthogonal transformation은 input에 대한 정보를 잃지 않기 때문입니다.
Theoretical Analysis
Universal approximation
우선 PointNet이 continuous set function에 대해 universal approximation ability가 있음을 보여줍니다.
여기서 continuous set function은 set을 input으로 받고, set에 대한 특성을 연속적으로 mapping 하는 함수입니다.
여기선
어떻게 g(h)가 f로 근사할 수 있는지에 대한 설명이 나옵니다. 자세한 증명은 supplementary에 나와있습니다.
이 부분은 생략하겠습니다.
Bottlenck dimension and stability
저자는 network의 표현력은 max pooling layer의 'dimension'에 따라 크게 달라진다고 합니다. (k)
이 부분에선 이에 대한 증명이 나와있습니다.
Experiment
experiments part는 크게 4가지로 나뉩니다.
1. multiple 3D recognition task에 적용된 예시
2. network design에 대해 validate하는 디테일한 실험들
3. network가 무엇을 학습하는지 시각화한 실험들
4. time, space complexity 분석
Applications
새로운 data representation (point sets)을 사용했는데도, 기존의 method들보다 좋거나 비슷한 성능을 냈습니다.
3D object classification, object part segmentation, semantic scene segmentation
3D Object Classification
object classification을 하기 위해선 global point cloud feature를 학습합니다.

PointNet은 point를 input으로 사용하고 SOTA를 달성했습니다. (only fully connected layers and max pooling)
또한 inference 속도도 빠르며 CPU에서 쉽게 병렬처리가 가능합니다. multi-view와 비교했을 땐 pointNet의 성능이 약간 떨어지는데, 이 이유는 rendering된 image에서 포착될 수 있는 geometry detail이 부족하기 때문이라고 주장했습니다.
3D Object Part Segmentation
part segmentation은 어려운 fine-grained 3D recognition task입니다.
3D scan이나 mesh model이 주어졌을 때, 각 point나 face에 대해 part category label을 할당하는 task입니다.

여기선 part segmentation은 point별 classification problem으로 나타냈습니다.
mean IOU에선 2.3% 성능이 향상됐고 대부분의 category에서 baseline method 만큼의 성능이 나왔습니다.
Semantic Segmentation in Scenes
network는 part sgementation은 semantic scene segmentation으로 확장가능합니다. point label이 object part label 대신 semantic object class가 됩니다ㅓ.




