https://arxiv.org/abs/2405.11315
MediCLIP: Adapting CLIP for Few-shot Medical Image Anomaly Detection
In the field of medical decision-making, precise anomaly detection in medical imaging plays a pivotal role in aiding clinicians. However, previous work is reliant on large-scale datasets for training anomaly detection models, which increases the developmen
arxiv.org
(anomaly detection task)
Abstract
medical decision-making 분야에서, medical imaging을 anomaly detection하는 것은 중요한 역할을 합니다. 그러나 기존의 연구들은 anomaly detection model을 학습할 때 거대한 dataset에 의존하기 때문에 development cost가 증가하게 됩니다. 이 논문에선 처음 few-shot setting으로 medical image anomaly detection task를 다루고, 이는 data를 모으고 annotation하는 데에 매우 비싼 특징이 있는 medical 분야에서 상당히 중요한 역할을 하게 됩니다. MediCLIP은 self-supervised fine-tuning을 통한 few-shot medical image anomaly detection을 위해 CLIP model을 적용하게 됩니다. vision-language model인 CLIP이 다양한 downstream task에서 뛰어난 zero-/few- shot 성능을 보여줬음에도 불구하고 medical image에서 anomaly detection의 성능은 좋지 않습니다(fall short). 이 문제를 해결하기 위해, medical imaing에서 공통된 질병 패턴을 시뮬레이션 하도록 anomaly synthesis task를 설계했고, 이는 CLIP의 강력한 generalization 능력을 medical image anomaly detection에 transfer하며 가능합니다.
Introduction
medical image anomaly detection task는 다양한 lesion 구역에 대해 normal과 anomalus image를 구분하고 각각 lesion area의 위치도 식별할 수 있습니다. 아무래도 lesion image가 부족하기 때문에, 이 분야에선 unsupervised anomaly detection setting에 집중해 연구했습니다. 여기서 model은 온전히 normal image에 학습이 되고, normal pattern에서 미묘한 차이들로부터 anomaly를 감지하게 됩니다.
이 논문에선 어려운 task인 few-shot medical image anomaly detection task에 초점을 맞춥니다. 각 medical anomaly detection task에서, 학습하는 동안 어떠한 anomaly image나 pixel-level label없이 few-shot normal image만 제공합니다. 이런 set은 medical anomaly detection model의 cost를 줄일 수 있고 medical data collection과 annotation의 process를 거치지 않아도 됩니다.
CLIP은 natural image와 raw text를 통합된 representational space로 mapping함으로써 강력한 generalization capability를 가지고, 이는 다양한 downstream task에 쉽게 적용될 수 있습니다. MedCLIP은 unpaired medical image와 text를 학습시켜 medical image classification에 CLIP의 capability를 확장했습니다. 그러나 이 방법은 lesion area를 알아내고 localize할 수 없는 단점이 있습니다. 최근 연구는 CLIP을 zero-/few-shot anomaly detction에 적용해 좋은 성능을 냈습니다. 그러나 이러한 방법들은 학습을 하는 동안 추가적인 실제 anomaly image와 이에 대응하는 pixel-level anomlay label이 필요하게 되고, 이는 medical field에서 얻기 어려운 것들입니다. 이런 한계를 다루기 위해, MediCLIP을 제안했고, 이는 추가적인 dataset을 사용하는 대신 model training에서 synthetic image를 사용합니다. 이 방식에서, 복잡한 구조의 인위적인 text prompt 대신 학습가능한 prompt를 사용해서, text embedding이 medical image에서 효과적으로 generalize 될 수 있게 합니다. 추가적으로 adapter를 사용해 CLIP vision encoder의 중간 layer feature를 learnable text feature와 align하도록 하고, 이는 multi-scale의 lesion localization capability를 가능하게 합니다.
MediCLIP의 성능을 3가지 medical imaging dataset에서 검증했습니다. chest X-ray image dataset인 CheXpert, brain MRI image dataset인 BrainMRI, breast ultrasound image dataset인 BUSI가 있습니다. few-shot learning setting에서, MediCLIP은 기존의 SOTA 방법과 비교했을 때 대략 10% 성능이 올랐습니다.
Method

우선 few-shot anomaly detection에 대한 문제 정의를 해야 합니다. 그다음 MediCLIP에 사용된 learnable prompt와 adapter에 대해 설명합니다. 마지막으로 medical image anomaly synthesis strategy에 대해 설명합니다.
Problem Definition
- few-shot anomaly detection task에 대한 정의
few-shot 학습 셋팅에서, n-way와 k-shot episode에 대해, support set D는 n개의 task로부터 normal image를 포함합니다.
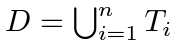
이 때 T(i)는 i번째 task에 대한 k개의 normal image를 포함합니다. test phase에서, n개의 task에 대한 query image들이 주어지고, 모델은 이 query image들이 anomalous한지 판단하도록, 그리고 이에 대한 anomalous image의 위치까지 알아내도록 학습됩니다. 다양한 medical anomaly detection task에 대해 많은 차이가 존재하기 때문에, medical system이 필요로 하는 것을 실제로 만족하기 위해, 여기선 n=1로 둬서 하나의 task에 대한 하나의 모델을 사용합니다.
Prompt Learning
CLIP에서, 'A photo of a [CLS]'와 같이 자주 사용되는 prompt는 주로 nature image의 전반적인 semantic한 정보를 설명하고, 이는 medical imaging에서 사소한 detail을 알아내기 위해 어렵습니다. 그렇기 때문에, anomaly detection에서 manual하게 만들어진 prompt대신 learnable prompt를 사용하고, 이는 복잡하게 prompt engineering할 필요없이 medical image에서 text embedding을 효과적으로 generalize할 수 있습니다. 구체적으로, 여기선 다음과 같은 prompt format을 활용합니다.
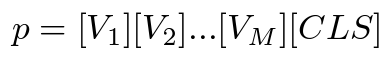
여기서 [V]와 [CLS]는 learnable word embedding과 prompt template에서 non-learnable class embedding을 표현하고, M은 학습가능한 token의 수를 의미합니다. class token에 대해선, [healthy]와 [normal]는 normal case과 [disease]에 대해선 anomalies 와 같이 의학적으로 관련있는 term을 사용하게 됩니다. 그러므로, normal과 anomalous case에 대해 P(n)와 P(a)이 가지고, P(n)과 P(a)는 noraml와 anomalous case에 대한 prompt set을 의미하고, I와 E는 P(n)와 P(a)에 포함되어 있는 class token의 갯수를 나타냅니다.
그리고 CLIP의 text encoder를 F(.)로 정의하고, F(.)는 prompt p를 feature representation F(p)로 mapping합니다.
그리고 각 prompt set P(n)과 P(a)에 대한 mean feature representation인 f(n),f(a)는 각각 다음과 같이 계산됩니다.

Adapting CLIP for Anomaly Detection
vanilla CLIP model은 zero-/few-shot image-text classification에 대해 설계된 것이고 anomaly detection이나 localization에 바료 적용할 수 없습니다. 여기선 vanilla CLIP model에 adapter를 추가해 적은 수의 learnable parameter를 통해 few-shot anomaly detction으로 적용시킨 것에 대해 설명합니다. 구체적으로 support set D에 대해 dimension이 RxWx3인 medical image가 있을 때, 여기서 랜덤하게 anomaly region mask Y (HxW)를 sample하고 여러 anomaly synthetic task에 대해 합성된 anomaly image인 X(hat)을 생성합니다.

이 때 Ψ는 anomaly synthesis function을 나타냅니다. CLIP의 vision encoder는 G(j)(.)로 나타내고, 이는 image의 j번째 layer feature를 뽑아냅니다. 그리고 이는 다음과 같이 표현합니다.

여기서 H(j),W(j),C(j)는 각각 height, width, channel의 수를 표현합니다. 결과적으로 image X(hat)에 대해, multi-scale visual feature set {G1(X(hat)),G2(X (hat)),..., GJ(X (hat))}을 얻게 됩니다. 각 중간 layer feature G(j)(X(hat))에 대해, adapter ϕj(·)를 사용해 prompt feature f(n)과 f(a)에 대해 일치하는 channel에 mapping시키고 결과적으로

다음과 같은 식을 얻습니다. 그 다음 g(j)에 대해 f(n)와 f(a)에 대한 spatial location (h,w)에 대한 similarity를 계산합니다.
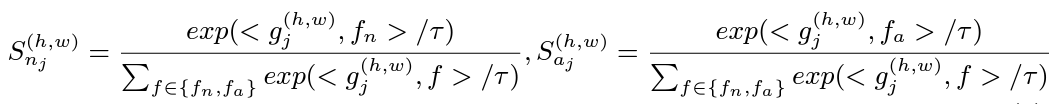
여기서 <.,.>는 cosine similarity를 의미하고, τ는 temperature parameter를 의미합니다. adapter에 의해 project된 각 visual feature g(j)에 대해, similarity matrix s(nj),s(aj)를 얻을 수 있습니다. 그리고 multi-scale similarity matrix sets {s(n1),s(n2),...,s(nj)}와 {s(a1),s(a2),...,s(aj)}에 대한 aggregation operation을 진행합니다. 그 다음 이들에 대해 HxW와 같은 spatial resolution으로 upsample 하고, S(n),S(a)에 대해 얻기 위해 average를 계산합니다.
learnable prompt와 adapter에 대한 parameter를 optimize하기 위한 loss function을 정의합니다.

각각은 Focal loss와 Dice loss를 나타내고 [.,.]는 channel에 대한 concat을 의미합니다. inference 할 때엔, query image를 X(hat)으로 사용해 anomaly synthesis task를 제거합니다. S(a)를 pixel-level anomaly map으로 활용하고, S(a)에서 maximum value는 image-level anomaly score로 사용됩니다.
Multi-task Anomaly Synthesis
multi-task anomaly synthesis는 source image X와 target mask Y가 주어졌을 때 anomlay image X(hat)을 생성합니다. 이 논문에선 3가지 종류의 anomaly synthesis task를 소개합니다 : CutPaste, GaussIntensityChange, Source이고 각각은 image blending, intensity variation, deformation에 해당합니다.

CutPaste
image patch를 임의로 선택하고 target location에서 붙입니다. 매끄러운 image blending을 위해 Poisson image editing을 활용한 업그레이드된 버전을 사용합니다. CutPaste task는 medical imaging에서 fracture와 같이 misplacement-like anomaly를 simulate할 수 있습니다.
GaussIntensityChange
Source
Experiments
Experimental Setup
Dataset
총 3개의 dataset에 대해 실험을 진행했습니다. (Stanford CheXpert dataset, BrainMRI dataset, BUSI dataset)
CheXpert dataset은 chest X-ray image를 갖고 12개의 질병을 다룹니다.
BrainMRI dataset은 normal과 tumor-affected case에 대한 2D human brain MRI image를 포함합니다.
BUSI dataset은 25세부터 75세까지 여성 환자들의 breast ultrasound image를 다룹니다.
이 이미지들은 normal, benign, malignant category로 분류되고, pixel-level로 질병의 위치가 annotation 되어 있습니다. 이 모든 질병에 대한 image를 anomaly로 다룹니다.
각 dataset에 대해 k={4,8,16,32}를 바꿔가며 학습을 진행했습니다. test할 때엔 CheXpert, BrainMRI, BUSI는 각각 250,65,101개의 normal image가 포함되고 250,155,647의 anomaly image가 포함됩니다.
Experimental Results

table1은 3가지 dataset에 대해 MediCLIP의 anomaly detection performance를 비교한 결과입니다. few-shot setting에서, 다른 방법들은 normal image가 부족하기 때문에 좋은 generalization을 얻기 어렵습니다. 반대로, anomaly synthesis task를 통해, MediCLIP은 CLIP 모델의 generalization capabilty를 medical anomaly detection에 잘 transfer했다고 볼 수 있습니다. MediCLIP은 다른 방법들에 비해 대략 10%이상의 성능 향상을 보였습니다.



