대학원 수업 'Deep Learning', 교재 'Understanding Deep Learning', 그리고 직접 찾아서 공부한 내용들을 토대로 작성하였습니다.
8장에선 model performance를 어떻게 측정하는지, 그리고 training data와 test data사이에 중요한 performance gap이 있다는 것에 대해 알아봤습니다.
1. model은 input에서 output까지의 실제 mapping을 대표하지 않는 training data의 통계적 특징을 묘사합니다(과적합).
2. training example들이 없는 영역에선 model은 아무런 제약을 받지 않기 때문에, suboptimal prediction들을 유도합니다.
Regularization
: generalization을 향상시키는 여러 전략들을 보통 regularization이라고 부릅니다.
크게 두가지로 분류할 수 있습니다.
1. explicit regularization
: loss function에 explicit term 추가하는 것 (특정 parameter에 조금 더 초점을 맞출 수 있도록)
2. implicit regularization
: 다양한 training algorithms (GD, SGD)
뿐만 아니라 data를 증가시키거나, 앙상블 기법을 적용하는 등 다양한 방법이 존재합니다.
처음엔 제일 엄밀한 기준에서의 regularization에 대해 설명한 뒤, 어떻게 stochastic gradient descent 자체가 특정 solution을 지지하도록 하는지 알아보겠습니다 (이런 방법을 implicit regularization이라고 합니다)!
마지막으로 test performance를 향상시키는 heuristic한 방법들에 대해 알아보겠습니다. 이후에 나오겠지만 이런 방법들에는 early stopping, ensembling, dropout, label smoothing, transfer learning이 포함됩니다.
Explicit regularization
input/output pairs 의 training set을 사용해 parameter Φ 를 갖고 있는 model을 fitting한다고 가정해봅시다.
minimum of loss function L[Φ]:

전체 loss function의 output은 각 data sample에 대한 loss function의 총 합과 같습니다. 이 때 각 data sample에 대한 loss function은 network의 예측 f[x(i), Φ]과 실제 output target value인 y(i) 간의 mismatch를 측정한 값입니다.
특정 solution에 대한 minimization에 치우치게 하기 위해 additional term을 추가합니다.

g[Φ]는 parameter가 덜 선호되면 더 큰 value를 취하도록 scalar값을 반환하는 함수입니다. 이 때, 해당 식은 loss function이기 때문에 식의 결과값이 최소화하도록 합니다. 만약 해당 parameter의 값이 크다면 loss function 입장에선 덜 선호하는 값이기 때문에 regularization의 term을 이용해 parameter의 값이 커지는 것을 방지한다고 볼 수 있습니다. term λ는 원래의 loss function과 regularization term의 상대적인 contribution을 조절하는 양수 값입니다.
Probabilistic interpretation
'minimizing loss' 를 'maximizing likelihood'로 볼 수 있습니다.

우리는 여기서 regularization term을 우리가 data를 관찰하기 전에 parameter에 대한 지식을 표현하는 'prior Pr(Φ)' 로 간주할 수도 있고, 이렇게 prior를 고려하는 criterion은 MAP (Maximum a Posterior) criterion이라고 볼 수 있습니다.

argmax를 argmin으로 바꾸기 위해 음수를 취하고, 계산의 편의성을 위해 log를 취해줍니다.
위에서 언급한
이 식과 비교해보면 λ* g[Φ]는 -log[ Pr(Φ) ] 로 볼 수 있습니다.
L2 Regularization
가장 흔히 사용되는 regularization term은 L2 norm입니다. 이 L2 norm은 parameter value들의 제곱의 합들에 대해 penalty를 부여합니다. L2 regularization 혹은 ridge regression으로도 불립니ㅣ다.

neural network에서, L2 regularization은 보통 bias에 적용되지 않고 'weight'에 적용하기 때문에 'weight decay' term이라고도 불립니다. 기존의 model보다 더 작은 weight를 갖도록 함으로서, output function이 좀 더 스무스 해지도록 합니다. 보충설명을 해보자면, output prediction은 마지막 hidden layer의 activation의 weighted sum이 됩니다. 만약 weight들이 작은 크기를 갖고 있다면 output들의 차이는 줄어들 것입니다. 같은 논리를 마지막 later의 pre-activation을 계산할 때에 적용하고, 그렇게 network를 통해 backward를 하면 같은 효과가 발생합니다.
이 때, weight를 0으로 두게 되면, network는 마지막 bias parameter로 결정되는 '일정한 output'을 뱉을 것입니다. (weight랑 곱해지는 term은 0이 되고 bias parameter만 남게 됨)

이 그림에서
- λ가 작으면, 작은 영향을 줍니다.
- λ가 커질수록, data에 대한 fit은 점점 덜 정확해지지만, function은 더 smooth해집니다.
그렇다면 이런 방법이 어떻게 test performance를 향상시킬 수 있을까요?
1. network가 overfitting이라면, regularization term을 추가하는 것은 '데이터에 완전히 맞추는 것'과 '모델을 smooth하게 하는 것'에 대한 trade off를 진행해야 한다는 의미입니다. variance에 대한 error(model이 더이상 모든 data point를 지날 필요없다)는 bias의 cost(model이 오직 smooth function만 묘사할 수 있다)로 줄어듭니다.
(If network is overfitting, adding regularization term means that the network must trade off slavish adherence to the data against the desire to the smooth)
2. network가 over-parameterized되면, 몇몇 여분의 model capacity는 training data가 없는 곳을 설명하게 됩니다. regularization term은 주변 point들 사이를 매끄럽게 보완하는 function을 장려할 것입니다. true function에 대한 지식이 없을 때 이런 방법을 사용하는 것이 제일 합리적입니다.
(when network is over-parameterized, some of the extra model capacity describes areas with no training data. Here, the regularization term will fave functions that smoothly interpolate between the nearby points.)
Implicit regularization
최근 연구에서 흥미로운 것은 우리가 알고 있는 gradient descent와 stochastic gradient descent 둘 다 loss function의 minimum에 중립적으로 다가가지 않다는 점입니다. 각각의 algorithm은 몇 solution에 대해 선호도를 갖고 있습니다.
이것을 우리는 implicit regularization이라고 합니다.
Implicit regularization in gradient descent
step size가 무한대인 continuous gradient descent가 있다고 가정해봅시다. parameters Φ의 변화는 differential equation으로 이뤄질 것입니다.

여기서 gradient descent가 이 과정을 무한대가 아닌 discrete한 α인 step size의 연속으로 접근할 수 있습니다.

이렇게 분리시킨 것은 continuous path로부터 '탈선'을 야기합니다.

이 그림에 대해 살펴봅시다. 이 그림은 gradient descent에서의 implicit regularization을 설명합니다.
a) horizontal line Φ1=0.61 에서 global minimum을 갖는 loss function입니다. 푸른 점선은 좌측하단에서 시작하는 연속적인 gradient descent path를 보여줍니다. 민트색 궤적은 'step size가 0.1인 discrete gradient descent'를 보여줍니다.
유한한 step size로 인해 path가 분기되어 결국 다른 final position에 도달하게 됩니다.b) 이러한 둘의 차이는 continuous gradient loss function에 squared gradient magnitude에 penalty를 주는 'regularization term'을 추가함으로써 근사시킬 수 있습니다. c) 그렇게 term을 추가함으로써, continuous gradient descent 경로는 original loss function에 discrete gradient descent가 수렴한 곳과 같은 곳에 수렴할 수 있게 됩니다.
( optimal point에서 Φ1의 값은 변하지 않았지만, Φ0의 값은 살짝 변했습니다. 결국 다른 final position에 도달)
정리하자면,
parameter update를 discrete step으로 나누지 않고, 시간의 연속 (t)에 따라 변화하는 것으로 보면,
시간에 따른 파라미터의 변화는 파라미터에 대한 loss function 미분 값이라고 생각할 수 있습니다.
즉, 이 방정식은 현재 parameter에서 loss function의 기울기에 비례해 파라미터가 변화한다는 것을 나타냅니다.
continuous한 버전의 gradient descent는 parameter가 시간에 따라 부드럽게 변화하지만, 실제로는 컴퓨터에서 이를 이산적은 단계로 구현해야 합니다. 그렇기 때문에, continuous parameter update를 discrete 단계로 '근사화' 해야합니다.
이것은 우리가 흔히 알고있는 gradient descent 방식입니다. parameter를 현재 위치에서 loss function의 음의 기울기 방향으로 작은 size만큼 이동시킵니다.
그렇기 때문에 continuous version의 gradient descent와 step size alpha로 discretization 한 gradient descent는 차이가 발생할 수밖에 없습니다.
continuous gd에서는 parameter가 연속적으로 시간에 따라 변화하고, 이것은 매우 이상적이긴 하지만, 실제로 컴퓨터는 연속적인 parameter update를 직접 구현하기 어렵습니다. 그렇기 때문에 continuous에 근접한 이산화된 버전의 gd를 하게 됩니다. 이 둘의 차이가 발생하는 이유가 무엇일까요?
우선 discrete한 step으로 update하게 되면, 각 단계에서 parameter는 이전 단계에서의 값과 현재 손실 함수의 기울기에 비례해 변화하게 됩니다. 이것은 continuous path를 따르는 것이 아니라 discrete한 이동을 하기 때문에, 차이가 발생합니다.
그리고, discrete version은 continuous version을 근사화한 것이므로, 근사화 과정에서 오차가 발생할 수 있습니다. 예를 들어, continuous에서는 매우 작은 시간 간격 내에서 parameter가 부드럽게 이동하지만, 이를 이산화 하게 되면 '특정 시간 간격(learning rate)'으로 근사화하기 때문에 오차가 발생할 수 있습니다.
이런 '탈선'은

이러한 수정된 loss term으로 이해할 수 있습니다.
다시 말하자면, 이런 discrte 궤적은 gradient norm이 큰 곳에서 이탈하게 됩니다. (surface가 가파른 곳)
이런 것들은 어쨌든 gradient가 0인 최소값의 위치를 바꾸진 않지만, 다른 곳에서 효과적인 loss function과 최적화 궤적을 수정해서, 잠재적으로 다른 minimum으로 수렴하게 됩니다.
(This doesn't change the position of the minima where the gradients are zero anyway However, it changes the effective loss function elsewhere and modifies the optimization trajectory, which potentially converges to a different minimum)
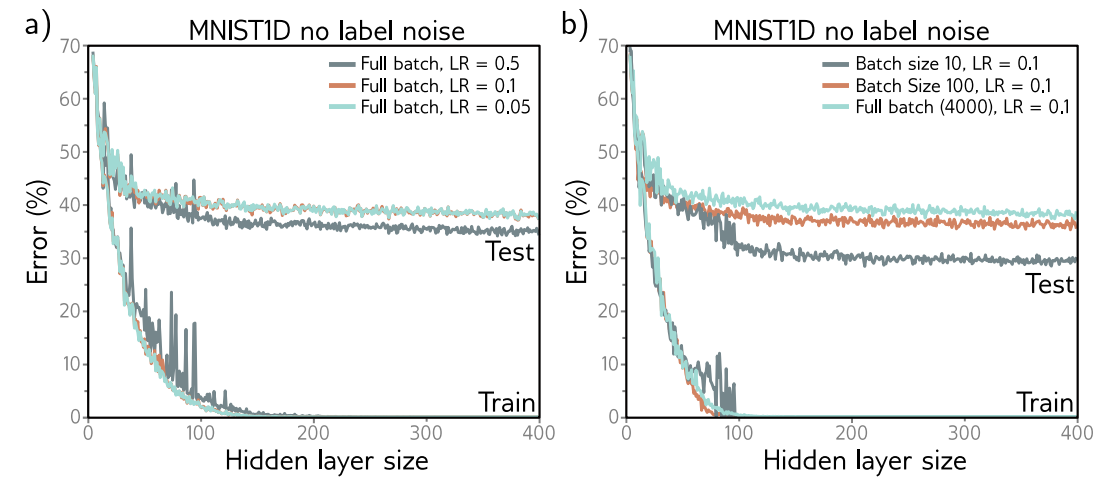
Gradient descent로 인한 implicit regularization에서 'full batch gradient descent는 step size가 클수록 더 generalize가 잘된다'는 점을 관찰할 수 있습니다. 물론 batch size가 더 작을수록 성능이 좋습니다.
Implicit regularization in stochastic gradient descent
비슷한 과정을 sgd에도 적용할 수 있습니다.
우리는 continuous version이 SGD update의 평균으로서 같은 위치에 있도록 하는 수정된 loss function을 찾고 있습니다.
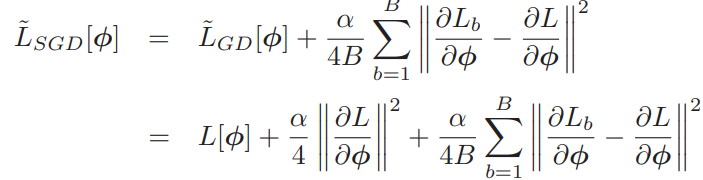
여기서 L(b)는 epoch에서 B batch에 대한 b번째 loss이고, L과 L(b)는 full dataset의 각각의 loss인 I의 mean을 표현하고, |B|는 batch의 개별적인 loss를 의미합니다.
여기서 gd로 인한 regularization term에 추가적인 term이 더 생겼고, 이 term은 batch loss Lb의 variance의 gradient에 대응합니다. 다시 말해서, SGD는 내재적으로 'gradient가 안정한 곳'을 더 선호합니다. 이는 optimization 과정의 trajectory를 수정하지만 global minimum의 위치를 반드시 바꾸는 건 아닙니다. 만약 model이 over-parameterized 됐다면, model은 모든 training data에 대해 완벽히 fit 할 것이고, 그렇다면 이 모든 gradient term은 global minimum에서 0이 될 것입니다.
SGD는 gradient descent보다 더 잘 generalize하고, batch size가 작을수록 generalize를 더 잘합니다.
이유에 대해 설명하자면 원래부터 존재하는 무작위성은 algorithm이 loss function이 다른 곳으로 도달하도록 합니다. 또 다른 관점에서 보자면, implicit regularization으로 인해 몇몇 혹은 모든 이 performance가 증가한다고 볼 수도 잇습니다. 이는 몇몇의 데이터만 아주 잘 fit하고 다른 data는 덜 fit한 solution (전반적인 loss는 같지만 더 큰 batch variance)보다 모든 data에 대해 잘 fit한 solution (batch variance가 작음)을 찾도록 합니다.


a) Gabor model의 original loss function (blue point가 global minimum)
b) gradient descent의 implicit regularization term (squared gradient magnitude에 penalty 줌)
c) stochastic gradient descent의 추가적인 implicit regularization (batch gradient의 variance에 penalty 줌)
d) 수정된 loss function (original loss function에 위에 두 regularization component의 합) (blue point는 panel (a)에서는 다른 위치에 있을 수 있음)
Implicit regularization : effect of learning rate and batch size
Early stopping
완전히 수렴되기 전에 training 절차를 중단하는 방법입니다.
model이 이미 대략적인 underlying function의 모양을 포착했지만 아직 noise에 대해서 overfit하지 않았다면, 이 방법을 통해 overfitting을 줄일 수 있습니다.

a) 14 linear region을 갖는 shallow network model이 random하게 초기화되고 batch size 5와 learning rate 0.05로 SGD를 사용해 훈련됩니다.
b-d) training 과정. function은 처음엔 true function(black curve)에 대해 조잡한 구조를 가집니다.
e-f ) noisy training data(orange point)에 대해 overfitting 일어남. training loss가 계속해서 감소해도, (c)와 (d)에서 보여지는 model이 훨씬 true underlying function에 가깝습니다. (c)와(d)가 (e)나(f)에 비해 더 test data에 대해 잘 generalize할 것입니다.
(loss function이 더 작다고 해서 더 잘 generalize한다는 보장 없음)
관점1
만약 weight가 작은 값으로 초기화 됐다면, early stopping을 하게 되면 단순히 값이 커질 시간이 없어지고, 이 효과는 explicit L2 regularization과 같은 효과를 갖게 된다고 볼 수 있습니다.
관점2
early stopping이 effective model complexity를 줄여줍니다. 그러므로, bias/variance trade-off curve아래로 이동시킴으로써, performance가 향상된다고 볼 수 있습니다.
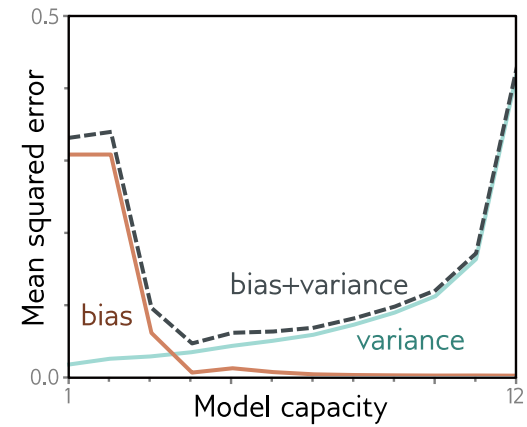
Early stopping은 몇 번의 step 후에 learning 종료할지에 대한 하나의 hyperparameter만 갖습니다. 보통, 이것은 validation set을 사용해서 경험적으로 선택합니다. 이 때 hyperparameter를 구하기 위해 여러 model을 traininig할 필요는 없습니다. model이 한 번 훈련되면, validation set의 performance는 모든 T iteration마다 확인할 수 있기 때문에, 관련된 모델은 저장됩니다. 이런 저장된 모델 중 validation performance가 제일 좋은 곳이 선택됩니다.
Ensembling
traininig data와 test data의 generalization gap을 줄이는 또 다른 방법은 다양한 모델을 만들고 그들의 prediction을 평균내는 것입니다. 이 때 average하는 방법들은 다양하게 있습니다.
그러나 이 방법의 단점은 다양한 model을 training하고 test 해야 하기 때문에 expensive 합니다.
(mathematical proof는 없음)
- regression problem : mean of the outputs / median of outputs
- classification problem : mean of the pre-softmax activations / most frequent predicted class
그냥 다른 random initialization을 사용하는 것도 다른 model을 학습하는 방법 중 하나입니다. 이는 training data에서 멀리 떨어진 input space region에서 도움이 될 수 있습니다. 여기서, fitted function은 상대적으로 unconstrained하고, 다른 model은 다른 prediction을 제공하기 때문에, 여러 model의 average는 단지 하나의 model보다 더 잘 generalize할 것입니다.
또다른 방법은 replacement와 함께 training data를 re-sampling하거나 각각에 대해 different model에 training을 시켜서 다양한 각각 다른 dataset을 생성하는 것입니다. 이는 'bootstrap aggregating' 혹은 'bagging'으로 많이 알려져 있습니다. 이 방법은 data를 smoothing하는 효과를 가집니다. 만약 어떤 data point가 한 training set에 존재하지 않는다면, model은 주ㅜ변 point로 부터 interpolate할 것입니다. 만약 그 point가 outlier 였다면, fiited function은 해당 구역에서 훨씬 더 적당한 형태를 취할 것입니다.

a) 전체 dataset에 대해 single model에 fit 한 것
b-e) 4번 replacement와 같이 data를 resampling해서 만든 모델 (orange point의 크기는 data point가 re-sample된 횟수를 의미합니다)
f) 이 ensemble의 prediction을 average 할 때, result(cyan curve)는 (a) panel의 결과보다 더 smooth 합니다. 이 때 (a)의 curve는 gray curve입니다.
Dropout

a) original network
b-d) 각 training iteration에서 hidden unit의 random subset이 zero로 clamped (gray node) 되었음.
결과는 이 unit들로부터 들어오고 나가는 weight에 대해선 변화가 없고, 매번 조금씩 다른 training을 할 수 있습니다.
dropout은 SGD의 각 iteration마다 hidden unit의 subset을 랜덤(보통 50%)으로 뽑아 0으로 만드는 방법입니다.
이 방법은 network가 어떤 주어진 hidden unit에도 덜 의존하게 만들고 weight가 더 작은 값을 갖도록 합니다. 이런 방법은 hidden unit의 존재 유무에 대한 변화를 줄이도록 합니다.
이 방법은 function에서 traininig data와 거리가 멀거나 loss에 영향을 주지 않는 원하지 않는 'kink'(뒤틀림)들을 줄일 수 있습니다.

예를 들어, 3개의 hidden unit이 그림의 curve에 따라서 순차적으로 활성화된다고 가정해봅시다. 첫번재 hidden unit은 slope를 크게 변화시킵니다. 두번째 hidden unit은 slope를 감소시키고, 그래서 function이 다시 내려가게 만듭니다. 마지막 unit은 이런 감소를 취소시키고, 원래의 궤적으로 곡선을 반환합니다. 이런 3개의 unit은 협력해 function에서 원하지 않는 local change를 만듭니다. 이건 traininig loss를 변화시키진 않겠지만 generalize를 잘하지 못할 것입니다.
몇몇의 unit이 이렇게 협력할 때, 하나를 제거하는 것은(dropout) 해당 unit이 활성화된 half-space로 전파되는 output function에 상당한 변화를 만듭니다.
이 때, 충분히 gradient descent step을 밟는다면 이렇게 발생하는 변화를 보상해줄 것이고, 이런 dependency를 시간이 지나면서 줄어들 것입니다. 이런 전체적인 효과는 training data point들 loss에 아무런 기여를 하지 않음에도 불구하고 data point들 사이에서의 커다란 불필요한 차이들이 점점 제거됩니다.
<inference>
test time에서 모든 hidden unit을 활성화시켜서 network를 작동시키면 됩니다. 하지만 그렇게 되면 network는 어떤 iteration 때보다 항상 더 많은 hidden unit을 갖게 되기 때문에, dropout probability에 -1의 weight를 곱합니다 (?) weight scaling inference rule
<정리>
- weight가 작아지도록 하면, function에서 hidden unit의 존재 유무에 따른 차이(change)를 감소시킵니다.
- 이렇게 hidden unit을 0으로 두면, 이 unit에 들어오는, 그리고 나가는 weight는 아무런 영향을 받지 않게 되고, 우리는 매번 조금씩 다른 network를 학습할 수 있게 됩니다.
이 그림에 대해 보충 설명해보자면,
a)는 우리가 원하지 않는 kink를 발견했을 때 입니다. 처음엔 slope가 올라갔다가 다시 내려가고, 다시 원래의 trajectory로 돌아가게 합니다. 여기서 우리는 full-batch gd 썼고, model이 최대한 data에 fit한 것입니다. 그렇기 때문에 training을 진행해도 저 kink는 사라지지 않을 것입니다.
b)에서 (a)에서 동그라미 친 부분을 만드는 hidden unit을 지웠다고 가정해봅시다. 그렇게 되면 slope가 다시 감소하지 않고 계속 증가(upward trajectory)하게 됩니다. 이렇게 slope가 감소되는 것 없이 training을 진행하게 되면, gradient descent step을 통해 이런 변화를 보완하려 할 것입니다.
c) 7,8,9 hidden unit 중 하나를 랜덤으로 drop out하며(kink 존재) 2000번의 iteration(gradient descent step)을 지났을 때, kink는 loss에 영향을 주지 않지만, dropout mechanism의 approximation에 의해 제거됩니다.
Applying noise
위에서 살펴본 dropout은 network activation에 Bernoulli noise의 곱셈을 적용한 것이라고 해석할 수 있습니다.
이런 관점은 model이 조금 더 robust 해질 수 있도록 network가 training 하는 동안 network의 다른 부분에 noise를 주도록 하는 아이디어를 이끌었습니다.
1. Noise to input data

input data에 noise를 더하면, 학습된 function을 조금 더 smooth하게 만들어줍니다.
Regression problem에서, input에 대한 network의 output의 derivative에 대해 penalty를 주는 regularizing term을 추가하는 것과 동일하다고 볼 수 있습니다.
좀 극단적인 변형으로는 'adversarial training'이 있는데, 이 방법은 output에 큰 변화를 주는 input의 작은 변동을 적극적으로 찾는 optimization algorithm입니다. 이것들은 최악의 경우 추가적인 noise vector라고 생각할 수 있습니다. adversarial training은 network의 weight를 직접 수정하는 것보다, network에 들어오는 input 자체를 조정합니다.
2. Noise to weight
이 방법은 weight의 작은 변동에도 분별력 있는 prediction을 하는 network를 만들도록 합니다. 이 방법의 결과는 training이 넓고 평평한 지역에서의 중간에 있는 local minima에 수렴하도록 합니다.(tend to generalize better) (여기서 각각의 weight을 바꾸는 것은 크게 중요하지 않습니다)
3. Noise to outputs(labels)
label 자체에 noise를 줄 수도 있습니다. multiclass classification을 위한 maximum-likelihood criterion은 absolute certainty로 올바른 class를 예측하도록 합니다. 끝에서, 마지막 network activation들은 옳은 class에 대해선 매우 큰 값으로 push되고, 틀린 class에 대해선 매우 작은 값으로 push됩니다. 이런 training label의 비율p가 정확하지 않고 다른 class와 동등한 확률로 속한다고 가정함으로써 이러한 'overconfident'한 행동을 막을 수 있습니다. 각 training iteration마다 label를 랜덤하게 바꾸면서 진행할 수도 있지만, 단순히 loss function을 'predicted distribution'과 'true label이 1-p 확률을 가지고 다른 class들이 동일한 확률을 갖는 distribution' 사이의 cross-entropy로 바꿔서 진행할 수 있습니다. 이 방법은 'label smoothing'이라고도 불리고, 다양한 시나리오에서 generalization을 향상시킵니다. (prevent overconfident prediction)
Bayesian inference
training phase에서 보통 maximum likelihood 방법은 model의 prediction에 대해 가장 그럴듯한 parameter와 bias를 선택하기 때문에 overconfident합니다. 그러나 많은 parameter는 다양하게 데이터와 호환될 수 있고 가능성이 약간 낮을 수 있습니다 (?).
이 Bayesian 접근은 parameter를 unknown variable로 여기고, Bayes rule을 이용해 training data {xi,yi}에 대해 conditioned 된 parameters Φ에 대한 distribution Pr(Φ{x(i),y(i)}) 에 대해 계산합니다.
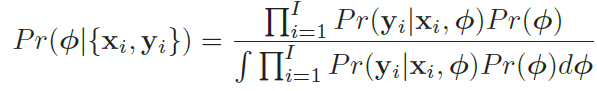
Pr(Φ) : parameter의 prior probability
분모는 normalizing term입니다.

새로운 input x에 대한 prediction y는 각 parameter set에 대한 prediction의 infinite weighted sum(integral)입니다. 이 때 weight은 probability와 연관되어 있습니다. (conditional distribution)
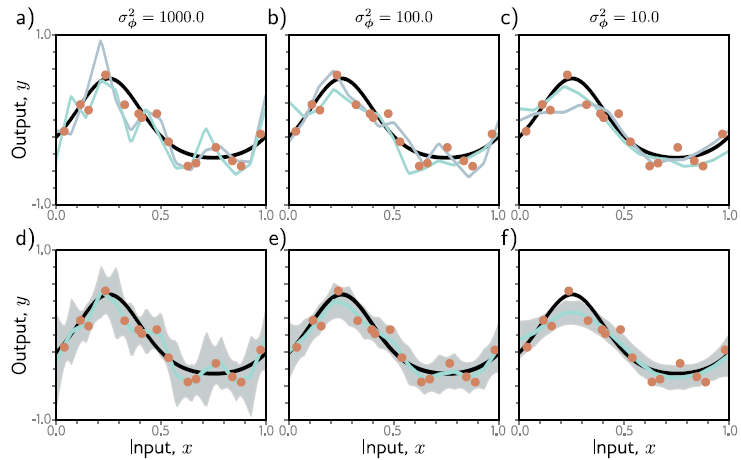
a부터 c는 mean zero, 3개의 variance에 대해 normally distributed prior를 사용한 posterior로부터 sampling한 두 set의 parameter입니다.
prior variance가 작을 땐, parameter도 작은 경향이 있고, function도 더 smooth해집니다.
d부터 f는 weight가 posterior probabilites인 모든 가능한 parameter value의 weighted sum를 통한 Inference 과정입니다. 이 과정은 모두 mean의 prediction(cyan curves)과 관련된 'uncertainty'(gray region)를 포함하고 있습니다. (variance가 클수록 uncertainty가 더 커집니다)
Bayesian approach는 고상하고 maximum likelihood로부터 도출된 prediction보다 더 robust합니다. 불행하게도, neural network와 같은 복잡한 모델은 parameter에 대한 full probability distribution을 표현하거나 inference 단계에서 합치는 현실적인 방법이 없습니다. 결과적으로 현재 존재하는 이런 type의 method는 어느정도 'approximation'을 하고 전형적으로 learning과 inference에 상당한 'complexity'를 추가하게 됩니다.
Transfer, multi-task, and self-supervised learning
training data가 한정적일 때, performance를 향상시키기 위해 다른 dataset을 사용할 수 있습니다.
Transfer learning

우선적으로 data가 더 충분한 관련 있는 secondary task에 대해 사용할 수 있는 network를 pre-train합니다.
결과로 얻은 모델을 original task에 적용시키고, 이 때 보통 마지막 layer를 제거하고 새로운 layer 하나 이상을 추가해 output에 적합하도록 만듭니다.
원칙은 secondary task로 부터 data의 좋은 internal representation을 짓고 이것을 original task에 사용할 수 있도록 하는 것입니다.
multi-task learning
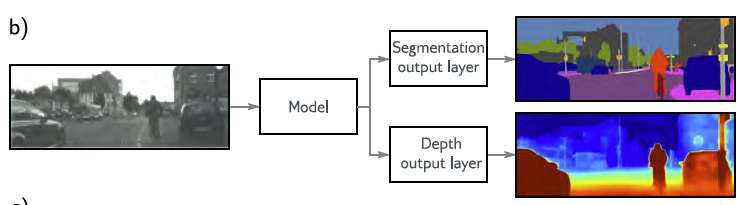
network가 동시에 여러 문제들을 해결할수 있도록 훈련됩니다.
이러한 모든 task는 image에 대한 이해가 필요하고, 동시에 훈련될 때, model performance가 향상될 것입니다.
위에서 본 transfer learning은 다른 dataset을 사용해 performance를 향상시킵니다.
multi-task learning은 추가적인 'label'을 사용해 성능을 향상시킵니다.
self-supervised learning

수많은 "free" labeled data를 만들고, transfer learning을 위해 사용하는 것입니다.
Self-supervised learning
- Generative self-supervised learning
: 각 sample의 부분은 'mask' 처리되고, secondary task는 missing part를 예측합니다.
1. unlabeled image에 대해선, image의 사라진 부분을 복원합니다.
2. 방대한 양의 text 말뭉치에 대해선, 몇 단어를 mask 처리하고 사라진 단어들을 예측하도록 network를 훈련하고
관심있는 실제 task에 대해 fine-tune을 진행합니다.
- Contrastive self-supervised learning
: 공통점을 가진 example의 pair들이 관련이 없는 pair와 비교합니다.
1. image에 대해서, image의 pair가 다른 것이 서로 변형된 버전인지 혹은 연관되지 않았는지 확인합니다
2. text에 대해서, 두 문장이 하나의 original document에서 나온 것인지 판단합니다.
Data augmentation
이 방법은 dataset 자체를 확장시킵니다. 각 input data example을 label을 동일하게 두고 다양하게 변형시킬 수 있습니다. ex) rotate, flip,blur, manipulate the color balance of the image 그리고 label은 그대로 둡니다.

비슷하게 input이 text인 task에 대해서도, synonym를 대체하거나 또다른 언어로 번역한뒤 다시 복구하는 방법이 있습니다.
data augmentation의 목표 : 이렇게 무관한 data 변형에도 개의치 않아하는 model을 만들어야 합니다.
Summary
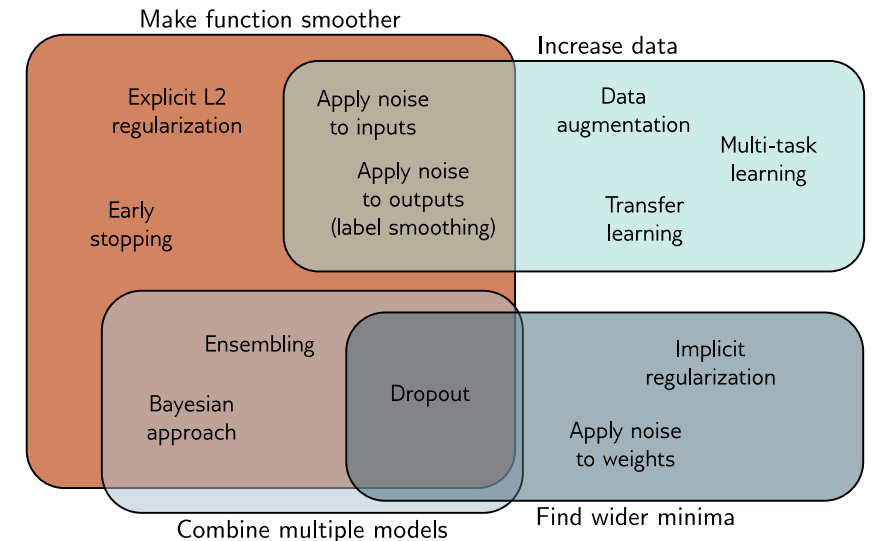
이번 챕터에서는 generalization을 향상시키기 위한 'regularization'에 대해 알아봤습니다.
- explicit regularization은 'minimum의 position'을 바꾸도록 loss function에 extra term을 추가하는 방법입니다.
- 추가된 extra term은 parameter에 관한 prior probability로 해석될 수 있습니다.
- finite step size의 stochastic gradient descent는 중립적으로 loss function의 minimum에 내려가지 않습니다.
- 이런 'bias'는 loss function에 추가적인 term을 추가하는 것으로 해석될 수 있고, 이것을 implicit regularization이라고 부릅니다.
- 뿐만 아니라 많은 heuristic 방법이 존재하는데, early stopping, dropout, ensembling, Bayesian approach, adding noise, transfer learning, multi-task learning, data augmentation 등이 있습니다.
이런 방법엔 4가지 원칙이 있는데,
1. function을 더 smooth하게 만들기 (L2 regularization)
2. data 양 늘리기 (data augmentation)
3. model 결합하기 (ensembling)
4. 더 넓은 minima 찾기 (network weight에 noise 적용)
-generalization을 향상시키는 또 다른 방법으로는 task에 맞는 model architecture를 선택하는 것입니다.
예를 들어, image segmentation에서 model의 parameter를 공유할 수 있고, 그렇기 때문에 모든 image의 location마다 독립적으로 tree가 어떻게 생겼는지 학습할 필요가 없습니다.
'Artificial Intelligence > Deep Learning' 카테고리의 다른 글
| 13. Unsupervised learning (0) | 2024.05.07 |
|---|---|
| 12. Graph neural networks (1) | 2024.05.03 |
| 11. Transformers (0) | 2024.04.23 |
| 10. Residual networks (1) | 2024.04.18 |
| 9. Convolutional networks (0) | 2024.04.16 |



