대학원 수업 'Deep Learning', 교재 'Understanding Deep Learning', 그리고 직접 찾아서 공부한 내용들을 토대로 작성하였습니다.
generative adversarial network , GAN은 training example의 set과 구분이 안되는 새로운 sample들을 생성하는 것을 목표로 한 unsupervised model입니다. GAN은 단순히 새로운 sample을 만들어내는 mechanism입니다. 모델링된 data에 대한 probability distribution을 설계하지도 않고 그렇기 때문에 같은 distribution에 대해 해석한 새로운 data point에 대한 probability도 평가할 수 없습니다.
GAN에서, main 'generator' network는 random noise를 output data space에 mapping함으로써 sample들을 생성합니다. 만약 secoe 'discriminator' network가 generated sample과 real example끼리 구분을 할 수 없다면, 생성된 sample들은 그럴듯한 sample이라고 볼 수 있습니다. 만약 이 network가 차이를 구분한다면, sample들의 퀄리티를 향상시킬 수 있도록 training signal을 다시 줍니다. 이 아이디어는 단순하지만, GAN을 학습시키는 것은 어렵습니다. learning algorithm이 불안정하고, GAN이 현실적인 sample들을 생성하도록 학습이 됨에도 불구하고, '모든' 가능한 sample을 생성하도록 학습된다고 보기 어렵습니다.
GAN은 audio, 3D model, text, video, graph와 같은 다양한 type의 data로 적용되었습니다. 이 중 가장 성공적인 분야는 image domain이고 실제 pidcture로부터 거의 구분할 수 없는 sample들을 생성할 수 있습니다. 따라서, 이 챕터에서 example을 image를 생성하는 것에 초점을 맞출 예정입니다.
Discrimination as a signal
우리는 실제 training data {xi}의 set에 대해 같은 distribution으로부터 생성된 새로운 sample {x*j}를 생성하도록 합니다. 새로운 single sample x*j는 (1) simple base distribution으로 부터 'latent variable zj'를 선택하고 (2) 이 data를 parameter θ에 대해 network x*=g[xi, θ]를 통과시킴으로써 얻을 수 있습니다. 이런 network를 'generator'라고 합니다. learning process 동안 목표는 samples {x*j}가 real data {xi}롸 비슷해 보이도록 parameter θ를 찾는 것입니다.
'similarity'는 다양한 방식으로 정의될 수 있지만, GAN은 'sample이 true data와 'statiscally indistinguishable'하다는 규칙을 사용합니다. 이를 위하여, discriminator라고 불리는 'parameter Φ에 대한 second network f[., Φ]'가 소개됩니다. 이 network는 real example 혹은 generated sample을 input으로 받고 이를 구분하도록 합니다. 이것이 불가능한 것으로 판명되면, generated sample은 real example로부터 구분할 수 없는 것이고, 이는 우리의 목표에 성공한 것입니다. 만약 가능하다면, discriminator는 generation process를 향상시키도록 하는 signal을 제공합니다.

다음 식이 GAN mechanism을 설명합니다. 실제 1D example의 training set {xi}로 시작해보겠습니다. 각 a,b,c는 각 panel에서 이 examples에서 나온 10개로 이뤄진 각각 다른 batch입니다. sample {x*j}의 batch를 생성하기 위해, 우리는 다음과 같은 simple generator를 사용합니다:

이 때 latent variables {zj}는 standard normal distribution으로부터 생성되고, parameter θ는 x축에 따라 생성된 sample로 해석합니다.
θ=3.0 로 initialization이 된 곳에선 생성된 sample(orange arrows)는 real example의 왼쪽에 생성되었습니다. discriminator는 real example로부터 generated sample을 구분하도록 학습됩니다. (sigmoid curve는 data point가 실제인지에 대한 probability를 나타냅니다). training 하는 동안, generator parameter θ는 sample들이 real data로 구분되도록 하는 probability를 높이는 방향으로 조작됩니다. 여기서, θ가 증가됐다고 볼 수 있는데, sigmoide curve가 더 높아지도록 sample들이 오른쪽으로 이동했기 때문입니다. 우리는 discriminator와 generator를 번갈아 update합니다. 위의 그림의 b-c는 이 process의 two iteration을 보여준 것입니다. 이는 갈수록 data를 classify하기 어려워지고, 그래서 θ를 바꾸려는 자극이 줄어듭니다. (sigmoid가 평평해짐) 이 과정 마지막에서, 이 두 set을 구분할 수 없게 됩니다. discriminator는 버리고, 그럴듯한 sample을 만들어내는 generator를 얻게 됩니다.
GAN loss function
GAN을 훈련시키기 위한 loss function에 대해 더 자세히 알아봅시다. discriminator f[x,Φ]는 inputs x를 받고, parameters Φ를 갖고, input이 real example로 여겨질 때 더 높은 값을 내도록 scalar 값을 반환합니다. 이는 binary classification task이기 때문에, binary cross-entropy loss function을 적용합니다.

yi는 0,1 중 하나의 값이고, sig[]는 logistic sigmoid function입니다. 이 상황에서, 우리는 real example x가 label y=1을 갖고, generated sample x*가 label y=0을 가졌다고 가정해봅시다.

i,j는 각각 real example과 generated sample의 index입니다.
이제 여기서 generator x*j=g[zj, θ]로 대체하고, 우리는 generated sample이 잘못 구분되길 원하기 때문에 θ에 대해 해당 값이 maximize되도록 합니다.
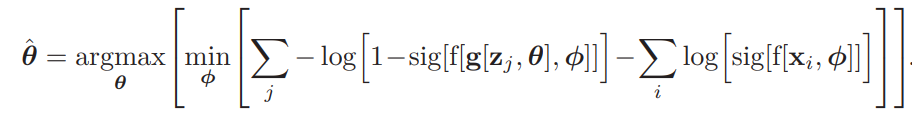
Training GANs
위의 식은 우리가 전에 봐온 것에 비해 더 복잡한 loss function입니다. discriminator parameters Φ는 loss function이 최소화되도록 조절되고, generative parameters θ는 loss function이 maximize되도록 조절됩니다. GAN training은 minimax game으로 특징지어 집니다. generator는 discriminator를 속이기 위해 새로운 방법을 찾고자 합니다. 이 때 새로운 방법은 generated sample과 real sample을 구별하는 새로운 방법입니다. 구체적으로, solution은 'Nash equilibrium' 이고 이는 동시에 하나의 function에 대해선 minimum이고 또 다른 function에 대해선 maximum인 position을 찾는 optimization algorithm입니다. training이 계획대로 진행된다면, 수렴이 되고, 이 때 g[z,θ]가 data에 대해 같은 distribution으로 생성됩니다. 그리고 sig[f[.,Φ]]는 발생할 가능성이 있습니다.
GAN을 훈련시키기 위해, 위의 식은 2개의 loss function으로 나눌 수 있습니다.

이 때 우리는 minimization problem으로 변형하기 위해 second function에 '-1'을 곱하고 θ와 상관없는 second term을 버립니다. 첫번째 loss function을 최소화하는 것은 discriminator를 학습시키니다. 두번째 minimizing은 generator를 학습시킵니다. 각 step에서, 우리는 base distribution으로부터 latent variables zj의 batch를 생성하고 sample x*j=g[zj, θ]를 생성하기 위해 generator를 통해 latent variable을 통과시킵니다. 그 다음 우리는 실제 training examples xj의 batch를 선택합니다. 두 개의 batch가 주어졌을 때, 우리는 이제 각 loss function에 대해 1개 이상의 gradient steps를 수행할 수 있습니다.
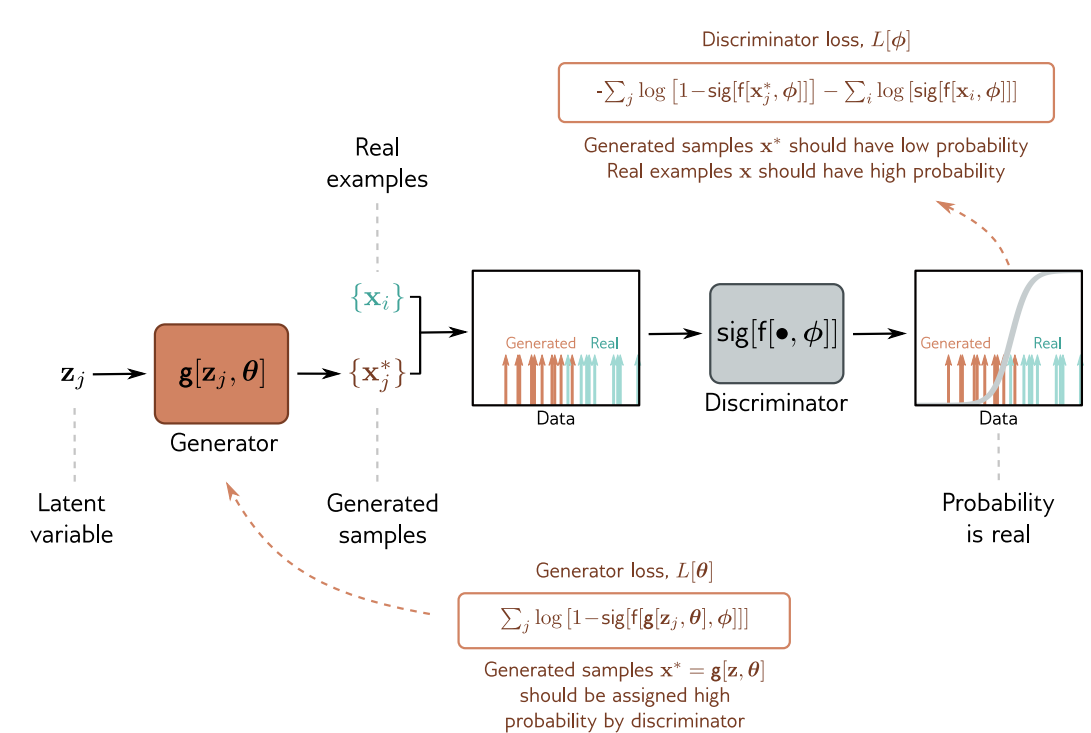
latent variable zj는 base distribution으로부터 생성되고 sample x*를 생성하기 위한 generator를 통과합니다.
sample의 batch {x*j}와 real examples {xi}의 batch는 discriminator로 통과되고, 이 때 각 example이 real인지에 대한 probability를 할당합니다. discriminator parameters Φ는 real example엔 높은 probability를, generated sample에 대해선 low proability를 할당하도록 수정됩니다. generator parameters Φ는 generated samples에 높은 probability를 할당하도록 멍청한 discriminator로 수정됩니다.
Deep convolutional GAN
deep convolutional GAN 혹은 DCGAN은 image 생성에 특화된 초기 GAN 구조입니다. generator g[z, θ]에 대한 input은 100D latent variable z이고 uniform distribution으로부터 sampling됐습니다. 그리고 linear transformation을 사용해 1024개의 channel을 가진 4x4 spatial representation에 mapping됩니다. 4개의 convolutional layer가 이어지고, 각각은 resolution을 두 배로 하는 fractionally-strided convolution을 사용합니다. 마지막 layer에선, 64x64x3 signal이 image x*가 [-1,1] 범위에서 생성하도록 하는 tanh function을 통과합니다. discriminator f[.,Φ] 는 마지막 convolutional layer가 하나의 channel로 size를 1x1로 줄이는 standard convolutional network입니다. 이렇게 생성된 single number는 output probability를 생성하기 위해 sigmoid function sig[.]를 통과합니다.
training 이후, discriminator는 버려집니다. 새로운 sample 만들기 위해, latent variable z는 base distribution으로 생성되고 generator를 통과합니다.

generator에서, 100D latent variable z가 function distribution으로 생성되고 4x4 representation with 1024 channel에 linear transformation에 의해 mapping됩니다. 그 다음 점점 representation은 upsample하고 channel의 수는 줄이는 convolutional layer의 series를 통과시킵니다. 마지막은 image를 표현할 수 있도록 고정된 범위에 대한 64x64x3 representation을 mapping하는 tanh function입니다. discriminator는 input으로 들어오는 real example이나 generated sample에 대해 구분하는 standard convolutional net으로 이루어져 있습니다.
Difficulty training GANs

이론적으로 GAN은 꽤 간단합니다. 그러나, GAN은 train이 어렵기로 악명 높습니다. 예를 들어, 믿을 수 있게 훈련하는 DCGAN을 얻기 위해선, (1) upsampling과 downsampling을 위한 strided convolution을 사용하고 (2) 마지막과 첫번째 layer를 제외한 각각 generator와 discriminator에 BatchNorm을 사용하고 (3) discriminator에 leaky ReLU activation function을 사용하고 (4) 평소보다 더 낮은 momentum coefficient를 사용한 Adam optimizer를 사용해야 합니다. usual하지 않습니다.. 대부분의 deep learning model은 상대적으로 이런 선택들에 대해 robust합니다. 일반적으로 실패하는 경우, generator는 그럴듯한 sample을 만들지만, 이는 단지 data의 subset만 나타낼 뿐입니다. 이런 경우 'mode dropping'이라 합니다.

이런 현상의 extreme version에선 generator가 완전히 latent variables z를 무시하고 하나 또는 몇 개 point로 모든 sample을 붕괴하는 경우 발생합니다. 이를 mode collapse라고 합니다.
Improving stability
GAN을 훈련하는 게 왜 어려운지 이ㅣ해하기 위해, 정확히 loss function이 '무엇을' 표현하는지 이해해야 합니다.
Analysis of GAN loss function
위에서 우리는 loss function을 두 합으로 분할했고, loss function은 expectation에 대해 다음과 같이 쓰일 수 있습니다.

이 때 Pr(x*)는 generated sample에 대한 probability distribution이고, Pr(x)는 real example에 대한 probability distribution입니다. I=J일 때, 모르는 origin의 example x~에 대한 optimal discriminator는 다음과 같습니다.

이 때 오른쪽은, x~는 generated distribution Pr(x*)와 real distribution Pr(x)에 대해 평가합니다.
결과적으로 다음과 같은 식이 생성됩니다.

additive와 multiplicative constant를 고려하지 않으면, 이는 synthesized distribution Pr(x*)와 true distribution Pr(x) 사이의 'Jensen-Shannon divergence'입니다.

이 때 D(KL)[.][.]는 Kullback-Leibler divergence입니다.
첫번째 term은 sample density Pr(x*)가 높을 때마다 distance가 작을 것이고, mixture (Pr(x*)+Pr(x))/2는 높은 probability를 가집니다. 즉, 이는 sample x*에 대한 region엔 penality를 주지만 real example x에 대해선 주지 않습니다.
=> 'quality'를 향상시킴.
second term은 true density Pr(x)가 높고, mixture (Pr(x*)+Pr(x))/2가 높은 probability를 가질 때마다, distance가 작아진 다는 것을 의미합니다. 즉, 이는 real example에 대한 region엔 penalty를 주지만 sample에 대해선 그렇지 않습니다.
=> 'coverage'를 향상시킴
위의 식에서 우리는 second term은 generator에 의존하지 않는다는 것을 알았고 이는 결국 coverage를 신경쓰지 않는다는 것을 의미합니다. 가능한 example의 subset을 정확하게 생성하면 좋습니다. 이것이 mode dropping의 추정 이유입니다.
Vanishing gradients
이전 section에서, 우리는 discriminator가 optimal일 때, loss function은 generated sample과 real sample간의 distance의 측정을 최소화하는 것입니다. 그러나, GAN를 optimizing하기 위한 criterion으로 probability distribution간의 거리를 사용하는 것은 문제를 야기할 수 있습니다. probability distribution이 완전히 disjoint라면, distance는 infinite이 될 것이고, generator에 아주 작은 변화도 loss를 줄이지 못할 것입니다. 같은 현상은 우리가 original formulation을 고려할 때도 볼 수 있습니다. 만약 discriminator가 완전히 generated sample과 real sample을 구분할 수 있다면, generated data에 대한 작은 변화는 classification score를 변화시킬 것입니다.

불행하게도, generated sample과 real sample의 distribution은 실제로 'disjoint'일 것입니다. real example은 또한 data를 생성하는 physial process로 인해 low-dimensional subspace에 놓여있습니다. 이런 subspace들 간의 overlap은 거의 없거나 아예 없을 수 있고, result는 아주 작거나 gradient가 없을 수 있습니다.

위의 그림은 방금 설명한 가설을 설명하는 empirical evidence입니다. DCGAN generator가 동결되고 discriminator가 반복적으로 업데이트돼서 classification performance가 향상되면, generator gradient는 감소합니다. 짧게 말해서, discriminator와 generator의 qulity간의 아주 미세한 balance가 존재합니다. discriminator가 너무 좋으면, generator의 training update는 약화됩니다.
Wasserstein distance
이전 section에서
(1) GAN loss가 probability distribution간의 distance에 대해 설명된다.
(2) 이 distance의 gradient는 generated sample이 real example로부터 너무 쉽게 구분되면 0이 된다.
는 것을 알 았습니다.
이를 해결하는 분명한 방법은 더 나은 특징을 가진 distance metric를 선택하는 것입니다.
'Wasserstaein' 혹은 'earth mover's' distance는 하나의 distribution이 다른 distribtuoin을 생성하기 probability mass를 운반하는 데 필요한 작업(work)의 양입니다. 여기서 "work"는 움직인 distance에 의해 곱해진 mass로 정의됩니다. 이 방법은 이전보다 더 좋아보입니다. Wasserstein distance는 distribution이 서로 분리되어 있고 서로 가까워질수록 부드럽게 감소하는 경우에도 잘 정의됩니다.
Wasserstein distance for discrete distributions
wasserstein distance는 discrete distrubiton에 대해 이해하기 가장 쉽습니다. k bins에 정의된 distribution Pr(x=i)와 q(x=j)를 고려해봅시다. 첫번째 distrubition의 bin i에서 두번째의 bin j로 옮기는 mass의 unit과 관련된 cost C(ij)가 있다고 가정해봅시다. 이 cost는 index들끼리의 absolute differrence |i-j|가 될 것입니다. 옮겨진 amount는 transport plan을 형성하고 matrix P에 저장됩니다.
Wasserstein distance는 다음과 같이 정의됩니다.

이 때 다음과 같은 제약사항들이 존재합니다.

즉, Wasserstein distance는 하나의 distribution의 mass를 다른 distribution으로 mapping하는 contrained minimization problem에 대한 solution입니다. 이는 우리가 거리를 계산하려고 할 때마다 P(ij)에 대한 minimization problem을 해결해야 하기 때문에 불편합니다. 다행히, small system의 equation을 쉽게 풀 수 있는 standard problem입니다. 이는 primal form의 linear programming problem입니다.

이 때 p는 움직이는 mass의 amount를 결정하는 vectorized elements P(ij)를 포함하고, c는 distance를 포함하고, Ap=b는 initial distribution constraint를 포함하고, p>=0는 mass가 non-negative인 걸 보장합니다.
모든 linear programming problem에 대해선 같은 solution에 대해 동일한 dual problem이 있습니다. 여기서, 우리는 initial distribution에 적용된 variable f에 대해 maximize합니다. 이 때 distance c에 의존하는 constraint도 고려해야 합니다. 이런 dual problem에 대한 solution은 다음과 같습니다.


다시 말해서, 우리는 adjacent value가 1이상으로 바꿀 수 없는 variable {fi}의 새로운 set에 대해 optimize합니다.
Wasserstein distance for continuous distributions
이런 결를 다시 continuous multi-dimensional domain으로 해석하면, equivalent of primal form은 다음과 같습니다.
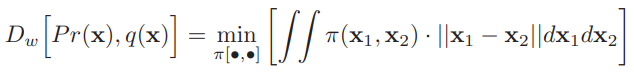
position x1에서 x2로 이동한 mass를 표현하는 transport plan π(x1, x2)의
과 유사한 제약 조건이 적용됩니다.
equivalent oof dual form은 다음과 같습니다.
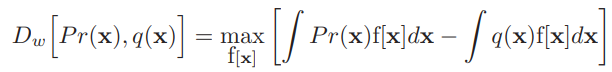
이 때 이는 function f[x]의 Lipschitz constant가 1보다 작다는 constraint에 따릅니다. (function의 absolute gradient는 1보다 작습니다)
Wasserstein GAN loss function
neural network의 상황에서, 우리는 neural network f[x,Φ]에서 parameter Φ를 최적화함으로써 function f[x]의 space를 최대화하고, 이 integral을 generated sample x*i와 real example xi를 사용해 근사시킵니다.

이 때 우리는 neural network discriminator f[xi, Φ]가 모든 position x에서 absolute gradient norm이 1보다 작도록 제약을 겁니다.

이를 달성하는 방법 중 하나는 discriminator weight를 작은 범위로 자르는 것입니다 (e.g.,[-0.01,0.01]).
대안은 'gradient penalty Wasserstein GAN 혹은 WGAN-GP'입니다. 이는 gradient norm이 unity에서 벗어날수록 증가하는 regularization term을 추가합니다.
Progressive growing, minibatch discrimination, and truncation
Wasserstein formulation은 GAN이 조금 더 안정적으로 훈련되도록 합니다. 그러나, high-quality image를 만들기 위해선 추가적인 기계가 필요합니다. 우리는 이제 output quality를 높이기 위해 'progressive growing', 'minibatch discrimination', 'truncation' 에 대해 알아봅니다.
'progressive growing'에서, 우리ㅣ는 처음 DCGAN과 비슷한 구조를 사용해 4x4 image를 생성하는 GAN을 훈련시켰습니다. 그다음 generator에 연속된 layer를 추가했고, 이는 representation을 upsample하고 8x8 image를 생성하기 위해 추가적인 process를 수행합니다. discriminator는 higher-resolution image를 받고 이를 generated sample인지 real sample인지 구분하기 위해 추가된 layer를 갖습니다. 실제로, higher-resolution layer는 시간이 지나면서 점점 "fade in" 됩니다. 초기에, higher-resolution image는 이전 결과의 upsampled version이고, residual connection을 지나고, 새로운 layer가 점차 자리를 잡습니다.
'mini-batch discrimination'은 sample이ㅣ 충분한 variety를 갖고 그렇기 때문에 mode collapse를 막아주도록 보장합니다. 이는 synthesize와 real data의 mini-batch를 걸친 feature statistics를 계산함으로써 실행할 수 있습니다. 이를 요약될 수 있고 feature map으로 추가할 수 있습니다(보통 discriminator의 끝 쪽). 이는 discriminator가 signal을 다시 generator에 보내도록 하고, original data set와 비슷한 amount의 변화를 synthesized data에 포함하도록 합니다.
generation result 향상시키는 또다른 trick으론 'truncation'이 있고, 오직 높은 probability를 가진 latent variable z가 sampling동안 선택됩니다. 이는 sample에서 variation은 줄이지만 quality는 높입니다. 신중한 normalization과 regularization scheme을 통해 sample quality를 향상시킵니다. 이런 method의 combination을 사용해, GAN은 다양하고 현실적인 image를 synthesize할 수 있습니다. latent space를 smooth하게 이동하면 synthesized image에서 다른 image로 realisitic interpolation을 생성할 수도 있습니다.
Conditional generation
GAN은 realistic image를 생성하지만 그들의 attribute을 구체화하지 않습니다. 각 특징의 combination에 대한 각각의 GAN을 훈련시키지 않는다면 우리는 머리색, 인종, 얼굴의 나이 등을 선택할 수 없습니다. 'Conditional generation' model은 이런 control을 제공합니다.
Conditional GAN
conditional GAN은 attribute의 vector c를 generator와 discriminator 모두에게 전달합니다. 이는 각각 g[z,c, θ]와 f[x,c,Φ] 로 쓰입니다. generator는 latent variable z를 correct attribute c와 같이 data sample x로 변형시키는 것을 목표로 합니다. discriminator의 목표는 (1) target attribute이 있는 generated sample 혹은 (2) real attribute이 있는 real example 을 구분하는 것입니다.
generator에서, attribute c는 latent vector z에 추가될 수 있습니다. discriminator에선, data가 1D라면 input에 추가될 것입니다. data가 image를 의미하면, attribute은 linear하게 2D representation으로 변형될 수 있고 discriminator input이나 중간의 hidden layer 중 하나에 extra channel을 덧붙입니다.

Auxiliary classifer GAN
auxiliary classifer GAN 혹은 ACGAN은 discriminator가 attribute을 정확히 예측하도록 요구함으로써 conditional generation을 단순화할 수 있습니다. C개의 category를 갖는 discrete attribute에 대해, discriminator는 input으로 real/synthesized image를 취하고, C+1 output을 갖습니다. 첫번째는 sigmoid function을 지나고 sample이 generate인지 real인지 예측합니다. 남아있는 output은 data가 각 C class에 속하는지에 대한 probability를 예측하기 위해 softmax function을 지납니다. 이 방법을 사용한 network는 ImageNet 통해서 여러 class를 synthesize할 수 있습니다.
InfoGAN
conditional GAN와 ACGAN 둘 다 predetermine된 attribute을 갖는 sample을 생성합니다. 반대로, InfoGAN은 자동적으로 중요한 attribute을 알아냅니다. generator는 random noise variable z와 random attribute variables c로 구성된 vector를 취합니다. discriminator는 image가 real인지 synthesized인지도 예측하고, attribute variable도 측정합니다.여기서 insight는 해석가능한 실제세계의 characteristics는 예측하기 제일 쉽고 그렇기 때문에 attribute variable c에서 표현된다는 것입니다. c에 있는 attribute들은 discrete 하거나 continuous할 것입니다. discrete variable은 data에서 category를 인식하고, continuous에선 variation의 gradual mode를 인식합니다.

a) MNIST database로부터 얻은 training example이며, 직접 쓴 digit의 28x28 pixel image로 구성되어 있습니다.
b) first attribute c1은 10개의 category가 있는 categorical한 attribute입니다. 각 column은 이 category들 중 하나에 대해 생성된 sample을 보여줍니다. InfoGAN은 10 digit을 복구합니다. attribute vector c2와 c3는 continuous합니다.
c) 왼쪽에서 오른쪽으로 볼 때, 각 column은 다른 latent variable은 일정하게 유지하면서 c2의 다른 값을 나타냅니다. 이 attribute은 character의 orientation에 해당하는 것처럼 보입니다.
d) 3rd attribute은 stroke의 thickness에 해당하는 것처럼 보입니다.
Image translation
adversarial discriminator가 random sample을 생성하기 위한 GAN의 context에서 처음 사용되었슴에도 불구하고, 이는 data example을 다른 example로 변환하는 task에서 'realism'을 favor하는 'prior'로 사용할 수 있습니다. 보통 image에서 사용되고, grayscale image를 color로 translate하거나, noisy image를 clean image로 하거나, blurry image를 sharp image로 하거나, sketch를 photo-realistic image로 하는 등에 사용할 수 있습니다.
이번 section에선 다른 양의 manual labeling을 사용하는 3개의 image translation model에 대해 알아보겠습니다. Pix2Pix model은 training에 대해 before/after pair을 사용합니다. adversarial loss를 가진 model은 main model에 before/after pair를 가지지만, discriminator에서 unpaired "after" image를 사용하기도 합니다. CycleGAN model은 unpaired image를 사용합니다.
Pix2Pix
Pix2Pix model은 parameter θ 와 같이 U-net를 사용해 하나의 image c를 다른 style image x로 mapping하는 network x=g[c, θ]입니다. 보통 colorization을 하는 경우에 많이 쓰이고, 이 때 input은 grayscale이고 output은 color가 됩니다. output은 input과 비슷해야 하며, 이는 input과 output 사이에 l1 norm ||x-g[c, θ]|| 의 penalty를 적용하는 content loss를 사용하며 권장됩니다.
그러나 output image는 input의 realistic conversion처럼 보여지기도 해야합니다. 이는 image c와 x 전후를 수집하는 adversarial discriminator f[c, x, ϕ]를 사용하여 권장됩니다. 각 step마다, discriminator는 real before/after pair와 before/synthesized pair 간의 구별을 하도록 합니다. 이를 성공적으로 구분할 수 있는 범위 내에서, U-Net을 output을 더 realistic하게 수정하기 위해 feedback signal이 제공됩니다. content loss는 large-scale image structure가 정확한 것을 보장하기 때문에, local texture가 그럴 듯 한지 확인하기 위해 discriminator가 주로 필요합니다. 이를 위해 PatchGAN loss는 순수한 convolutional classifier를 기반으로 합니다. 마지막 layer에서, 각 hidden unit은 receptive field안에 있는 region이 real인지 synthesized한지를 나ㅏ타냅니다. 이런 응답은 최종 output을 제공하기 위해 평균화됩니다.
이 model을 생각해볼 수 있는 한가지 방법은 U-Net이 generator인 conditional GAN이고 label보다 image에 conditioned 된다는 것입니다. 그렇지만 U-Net input은 noise를 포함하지 않기 때문에 conventional 관점에서 진짜 "generator"는 아닙니다. 흥미롭게도, original author는 input image c에 noise z를 추가해 U-Net의 input으로 사용하는 것을 실험해봤지만, network가 이를 학습하진 않았습니다.

a) model은 input image을 U-Net을 사용해 다른 style로 translate합니다. 이 경우, grayscale image를 그럴듯하게 color로 바뀐 version으로 mapping합니다. U-Net은 두 개의 loss로 학습됩니다. (1) content loss는 output image가 input image와 비슷한 구조를 갖도록 장려합니다. (2) adversarial loss는 grayscale/color image pair를 이런 image의 각 local region에서 실제 pari과 구별할 수 없도록 장려합니다. 이 framework는 b,c,d,e와 같은 다양한 task에 적용될 수 있습니다.
Adversarial loss
Pix2Pix model의 discriminator는 image translation task에서 before/after pair가 그럴듯한지를 구분하도록 했습니다. 이는 discriminator loss를 얻기 위해 ground before/after pairs가 필요하다는 단점이 있습니다. 다행히, 추가적인 labeled training data 필요 없이 supervised learning 상황에서 adversarial discriminator의 power를 이용할 수 있는 간단한 방법이 있습니다.
adversarial loss는 discriminator가 supervised network의 output을 real example과 output domain을 구별할 수 있는 경우 penalty를 추가합니다. 따라서 supervised model은 이런 penalty를 줄이기 위해 prediction을 변경합니다. 이는 Pix2Pix 알고리즘에서처럼, 전체 output의 scale이나 patch level에서 수행될 수 있습니다. 이는 복잡한 구조의 output의 realism을 향상시키도록 돕습니다. 그러나, original loss function 측면에서 반드시 더 나은 solution으로 이어지는 것을 아닙니다.

super-resolution GAN 혹은 SRGAN은 이 방법을 사용했습니다. main model은 redisual connection이 포함된 convolutional network로 이루어져 있는데 이는 저해상도의 image를 수집하고 upsampling layer를 통해 고해상도 image로 변형합니다. network는 3개의 loss로 학습됩니다. content loss는 output과 true high-resolution image사이의 squared difference를 측정합니다. VGG loss (혹은 perceptual loss)는 synthesized와 ground truth output를 VGG network에 통과시키고 각각의 activation의 squared difference를 측정합니다. 이는 image가 target에 의미적으로 비슷하도록 장려합니다. 마지막으로 adversarial loss는 실제 고해상도 image인지 아니면 upsample된 것인지 구분하도록 하는 discriminator를 사용합니다. 이는 output이 real example로부터 구분할수없도록 장려합니다.
CycelGAN
adversarial loss는 우리가 main supervised network에 대해 label된 before/after image를 갖고 있다고 가정합니다. CycleGAN는 우리가 구분되는 style의 2 set의 data를 갖고 있지만 matching pair가 없는 상황에서 다룰 수 있습니다. 어떤 사진을 Monet의 style로 바꾼 것이 예시입니다. 많은 photo가 있고 많은 Monet painting이 있지만, 그 둘끼리의 correspondence는 없습니다. CycleGAN은 image를 다른 방향 (photo->Monet)으로 바꿔서 다시 origianl로 복구하는 idea를 사용했습니다.
CycleGAN loss function은 3개의 loss의 weighted sum입니다. content loss는 before과 after image가 비슷하도록 장려하고 l1이 기반이 됩니다. adversarial loss는 output으 target domain의 실제 example과 구분할 수 있도록 장려하기 위해 discriminator를 사용합니다. 마지막으로, cycle-consistency loss는 mapping이 reversible할 수 있도록 장려합니다. 여기서, 두 model은 같이 학습됩니다. 하나는 first domain은 두번째 domain으로 mapping하고, 또다른 하나는 반대 방향으로 mapping합니다. cycle-consistency loss는 translated image 자체를 원래 doamin의 image로 성공적으로 다시 변환할 수 있는 경우 값이 작습니다. model은 이 3개의 loss를 합쳐 network가 image를 다른 style로 바꾸고 다시 원래로 바꾸도록 훈련합니다.
StyleGAN
StyleGAN은 dataset의 variation을 의미있는 component로 분할하는 보다 현대적인 GAN입니다. 이 때 각각은 latent variable의 subset에 의해 control됩니다. 특히, styleGAN은 output image를 다른 scale로 control하고 style을 noise로부터 분리합니다. face image 같은 경우, large-scale 변화는 face shape과 head pose를 포함하고, medium-scale 변화는 facial feature의 shape와 detail을 포함하고, fine-scale 변화는 hair와 skin color를 포함합니다. style component는 인간의 두드러진 측면에 대해 나타내고, noise 측면은 중요하지 않은 variation을 나타냅니다.
우리가 지금까지 본 GAN은 standard base distribution으로부터 도출된 latent variable z로 시작했습니다. 이는 output image를 만들기 위해 convolutional layer의 series를 지났습니다. 그러나 generator의 latent variable input은 (1) architecture에서의 다양한 point로 보일 수 있고 (2) 이 point에서 다른 방법으로 현재 representation을 바꿀 수 있습니다. StyleGAN은 이 choice들을 더 현명하게 scale를 조절하고 noise로 부터 style를 분리합니다.
StyleGAN의 main generative branch는 512 channel을 가진 학습된 constant 4x4 representation으로 시작합니다. 이는 image를 마지막 resolution으로 생성하기 위해 representation을 점점 upsample하는 convolutional layer의 series를 통과한다. style과 noise를 나타내는 2 set의 random latent variables는 각 scale에 도입ㄴ됩니ㅣ다.
noise 나타내는 latent variable은 독립적으로 Gaussian vectors z1, z2.. 를 sampling되고 main generative pipeline에서 각 convolution operation이후에 추가적으로 주입됩니다. 그들은 그들이 추가된 시점에서의 main representation과 같은 spatial size를 갖지만, channel마다 존재하는 학습된 scaling factors (ψ1, ψ2)에 의해 곱해집니다. 그리고 각 channel에 다른 양만큼 기여합니다. network의 resolution이 증가할수록, noise는 더 미세한 scale로 기여합니다.
style 나타내는 latent variable는 1x1x512 noise tensor로 시작하고, 중간 variable w를 만들기 위해 seven-layer fully connected network를 지납니다. 이를 통해 network는 style의 측면을 decorrelate할 수 있기 때문에 w의 각 dimension은 head pose나 hair color와 같은 independent한 real-world factor를 나타낼 수 있습니다. 이 variable w는 2x1x512 tensor y로 linear하게 변형되고, 이는 noise를 추가한 후 main branch의 spatial position에 걸친 representation의 channel 별 mean과 variance를 설정하는 데 사용됩니다. 이는 'adpative instance normalization'이라 불립니다. vectors y1,y2.. 의 series는 main branch에서 몇몇의ㅣ 다른 point에 이런 방법으로 주입되어, 같은 style이 다른 scale로 기여됩니다.

main pipeline은 constant learned representation으로 시작합니다 (gray box). 이는 convolutional layer series를 지나고 점점 upsample되며 output을 만듭니다. noise는 각각 다른 scale로 추가됩니다. gaussian style variable z는 fully connected network를 지나며 중간 variable w를 만듭니다. 이는 pipeline에서 다양한 point에서의 각 channel의 mean과 variance의 set으로 사용됩니다.

위의 그림은 다른 scale로 style과 noise vector를 조작한 예시입니다.
처음 4개의 column은 다양한 scale에서 style에 systematic change를 보여줍니다. 5번째 column운 noise magnitude이 증가될 대의 효과를 나타냅니다. 마지막 두 column은 각 다른 scale의 noise vector를 보여줍니다.
Summary
GAN은 trainingset으로부터 구분할 수 없는 data에 random noise를 변형하는 generator network를 학습합니다. 이를 위해, generator는 generated sample로부터 real example를 구분하도록 하는 discrinimator network를 사용해 학습됩니다. generator는 그 ㄷ다음 data가 discriminator에 의해 더 "real"처럼 인식되도록 생성하도록 update됩니다. 이 idea의 original formulation은 sample이 real인지 generated인지 쉽게 구분될 때 training signal이 약하다는 결점이 있습니다. Wassertein GAN은 더 일관된 training signal을 제공하며 이 단점을 해결했습니다.
우리는 image generation을 위한 convolutional GAN과 'progressive growing', 'mini-batch discrimination', 'truncation'을 포함해 generated image의 quality를 높이는 일련의 trick에 대해 알아봤습니다. conditional GAN architecture는 output (object class 선택 등 )을 control할 수 있는 auxiliary vector를 도입합니다. Image translation task는 이런 conditional information을 image 형태로 유지하지만 random noise를 제거합니다. GAN discriminator는 "realistic" 처럼 보이는 image를 선호하는 additional loss term으로 사용됩니다. 마지막, 우리는 StyleGAN을 알아봤고, 이는 generator에 noise를 주입해 전략적으로 style과 noise에 다른 scale로 control할 수 있습니다.
'Artificial Intelligence > Deep Learning' 카테고리의 다른 글
| 13. Unsupervised learning (0) | 2024.05.07 |
|---|---|
| 12. Graph neural networks (1) | 2024.05.03 |
| 11. Transformers (0) | 2024.04.23 |
| 10. Residual networks (1) | 2024.04.18 |
| 9. Convolutional networks (0) | 2024.04.16 |



