https://arxiv.org/abs/2003.08934
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
We present a method that achieves state-of-the-art results for synthesizing novel views of complex scenes by optimizing an underlying continuous volumetric scene function using a sparse set of input views. Our algorithm represents a scene using a fully-con
arxiv.org
이번에 공부할 논문은 NeRF입니다. ECCV 2020 oral에서 Best paper로 선정된 논문으로, 논문이 발표된 이후 Visual computing에서 계속해서 인용되어 왔습니다. 현재는 NeRF를 활용한 많은 연구가 진행이 되었습니다.
Introduction
우선 논문 내용에 대해 알아보기 전에 알아야 하는 개념에 대해 정의해보겠습니다.
제목에서 알 수 있듯이 NeRF는 '(novel) view synthesis'를 위해 Neural Radiance Fields를 사용해 scene을 표현하는 것이라고 보면 됩니다.
Novel View Synthesis

novel view synthesis는 어떤 object나 scene에 대해 여러 방향으로 찍은 2D image를 갖고 있을 때, 이를 이용해 우리가 갖고 있지 않은 새로운 방향에서 보이는 2D image를 얻는 task입니다.
NeRF는 이런 task를 수행하는 하나의 method라고 보시면 됩니다.
NeRF는 Neural Radiance Fields의 약자입니다. 그렇다면 이 말은 무슨 뜻일까요?
이 말을 이해하기 위해선 neural field, 그리고 field에 대한 개념을 알고 있어야 합니다.
Field
field는 원래 물리학 분야에서 생긴 용어입니다.
"Quantity defined for all spatial and/or temporal coordinate"
어떤 시/공간 좌표에 대해 정의된 '양'입니다.

예시에서 알 수 있듯이, 우리가 2D circle에선 field quantity가 반지름 r이 됩니다. Image에선 RGB intensity가 됩니다.
여기서, field를 어떤 coordinate을 input으로 받고 output으로 physical quantity를 뱉는 function으로 간주할 수도 있습니다.
그렇다면 nerual field는 무엇일까요?
Neural Field
neural field는 neural network에 의해 전체가 혹은 부분적으로 parameterized되는 field를 말합니다.
visual computing 분야에선 그냥 coordinate-based neural network를 neural field라고 한다고 합니다.
그럼 다시 NeRF에 대해 돌아가겠습니다.
NeRF는 novel view synthesis를 하는 task이고, novel view synthesis는 3D object나 scene에서 새로운 2D image를 얻는 것입니다. 그렇다면 이 3D scene을 어떻게 표현해야 할까요?
Scene representation of 3D
흔히 알고 있는 3d representation 방법엔 2D를 pixel로 표현하는 것처럼 3D voxel로 표현하거나, mesh, point cloud등을 사용합니다. 그러나 이는 discrete하고, voxel 같은 경우엔 acubic으로 저장해야 할 정보가 너무 많아지기 때문에 이러한 이유들로 high-resolution을 표현하기 어렵습니다.
대신, implicit representaiton 방법을 사용할 수 있습니다.
NeRF에선 MLP로 parameterized한 continuous function을 학습시켜 3D의 정보를 뽑아낼 수 있습니다.
그렇다면 이제 본격적으로 NeRF의 method에 대해 알아보겠습니다.
Method
overview
NeRF의 전반적인 흐름은 이렇습니다.
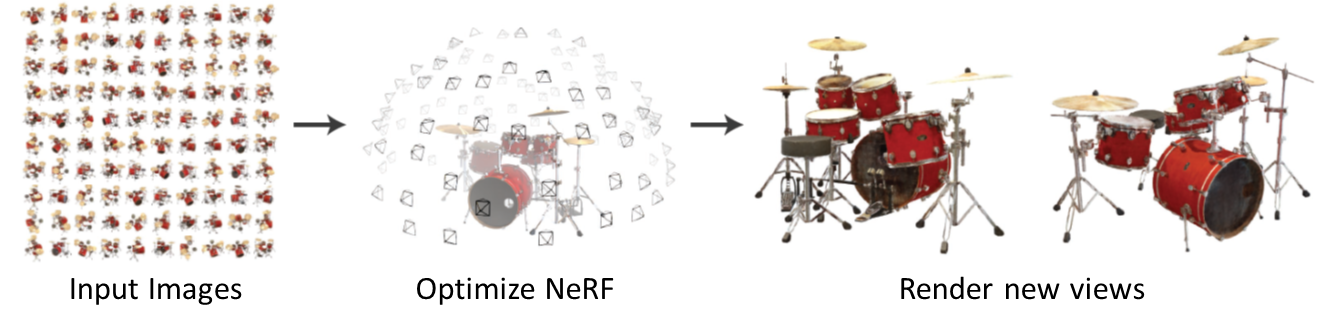

하나의 scene에 대해 여러 방향에서 얻은 2D image을 얻습니다. 이 때 2D image 뿐만 아니라 각 image에 대한 viewing direction (방향)도 고려합니다. 2D image와 그 때의 direction을 이용해 voxel과 direction을 input으로 하고 그 voxel의 color와 density가 나오는 fully connected neural network를 학습시킵니다. 이렇게 학습시킨 fully connected neural network을 이용해 color들을 축적해 2D image color들을 만듭니다.
NeRF의 전반적인 training 과정에 대해 알아보겠습니다.

1. viewpoint selection
우리가 바라볼 viewpoint를 선택합니다
2. ray composition
선택한 viewpoint에 대한 ray를 구성합니다.
3. select 5D input samples along the ray
ray 선상에 있는 point들을 sample합니다.
4. query into MLP
sample한 point들을 사용해 MLP의 output을 예측합니다.
5. get predicted color+density
color와 density를 예측합니다.
6. render color using volume ray casting
volume ray casting를 사용해 2D image pixel의 color를 render합니다.
7. compute rendering loss
loss function을 사용해 rendering loss도 computing합니다.
Classic volume rendering
NeRF에 있는 MLP는 voxel coordinate과 viewing direction을 줬을 때 해당 voxel의 color와 density를 반환한다고 했습니다.
그렇다면 이 MLP를 이용해서 어떻게 2D image를 생성할 수 있을까요?

우리의 눈, 혹은 카메라의 원점이 camera origin o라고 해봅시다.
o에서 뻗어나가는 방향벡터를 d라하고 t를 임의의 값이라고 했을 때, 우리는 origin에서 뻗어나가는 r(t)=o+td ray를 생각해볼 수 있습니다. 해당 ray를 지나는 2D image의 pixel에서의 color를 C(r)로 구할 수 있습니다. 3D object나 scene에서 제일 가까운 point tn에서부터 제일 먼 point tf 까지의 모든 point들에 대한 color와 volume density를 MLP(FCNN)을 통해 구할 수 있습니다. 이렇게 구한 color와 volume density를 사용해 C(r)를 구할 수 있게 됩니다.

C(r)의 식을 자세히 알아보겠습니다. 앞서 말한 tn에서 tf까지의 integral이고, c(r(t),d)는 해당 point에서의 color이고, sigma는 해당 point에서의 volume density가 됩니다. volume density를 고려하는 이유는 해당 point에서 어떤 color를 갖냐와 상관없이 만약 해당 point가 실제 물체가 있는게 아닌 공기 중의 point라면 해당 point를 고려하는 것이 의미없어집니다. 각 point의 투명도(밀도)를 고려하며 color를 축적해야합니다. 그리고 T(t)는 tn에서 t까지, 즉 해당 point보다 앞에 있는 point들의 투명도(밀도)도 고려해야 합니다. 해당 point에 물체가 존재하더라도 이미 앞에 밀도가 높은 물체가 있다면 현재 point가 갖고 있는 color는 큰 영향을 끼치지 못하기 때문입니다.
T(t)의 식은 위와 같습니다.

위의 그림은 exp(-x)의 식입니다. exp(-x)의 특징은 커질수록 0에 수렴하고, 0에 가까울수록 1에 가까워집니다.
exp(-x)에서 x에 해당하는 앞의 밀도들의 integral은 앞의 point들에 density가 높다면 값이 점점 커지면서 해당 point의 기여도가 낮아지게 되는 기능을 하게 되고, density가 낮다면 1에 가까워져 해당 point의 density와 color를 제대로 기여하게 됩니다. 논문에선 T(t)를 ray가 다른 입자와 부딪히지 않고 tn에서 t까지 나아갈 확률이라고 언급했습니다.
Volume Rendering with Radiance Fields
우리는 FCNN을 이용해 해당 voxel에서의 color와 density를 구하고, 이 output들을 이용해 2D image의 pixel의 color를 구할 수 있습니다. 그리고 이 output들의 값을 integral형태로 color를 구하게 되는데, 우리는 integral의 모든 point들을 사용하는 데엔 한계가 있습니다.
우리는 여기서 모든 point들을 사용하지 않고 point들을 sampling하게 됩니다.

모든 point들에 대해선 integral을 사용했지만, point들을 sampling 한다면 C(r)의 식은 summation의 형태로 바뀌게 됩니다. 여기서 delta는 하나의 point에서 다음 point까지의 거리입니다. integral에서 dt를 대신하는 역할입니다.
그리고 simga함수 대신 1-exp(-sigma*delta)로 바뀌게 됩니다. 여기서 만약 단순히 integral을 summation으로 바꾼다면 sigma*delta 가 되어야 하는데 굳이 1-exp(-sigma*delta) 형태로 바꾸는 이유는 이 논문에서 언급한 다른 논문에서 C(hat)(r)를 C(r)로 approximation 하는 것이 더 근사된다는 것을 증명해 이런 방법을 사용한다고 합니다.



