https://arxiv.org/abs/1701.02426
Scene Graph Generation by Iterative Message Passing
Understanding a visual scene goes beyond recognizing individual objects in isolation. Relationships between objects also constitute rich semantic information about the scene. In this work, we explicitly model the objects and their relationships using scene
arxiv.org
이 모델은 standard RNN을 이용해 scene graph inference 문제를 해결하고, message passing을 통해 반복적으로 예측 성능을 향상하도록 학습할 수 있습니다.
joint inference는 object들과 그들의 관계에 대해 더 좋은 예측을 할 수 있도록 도와주는 contextual 단서로 활용할 수 있습니다.
Scene graph
: visually-grounded graph over the object instances in an image, where the edges depict their pairwise relationships
하지만 기존의 이런 모델들은 ground-truth annotation, synthetic images 에 의존하거나, text domain으로부터 scene graph를 추출해야 합니다. 이런 'rich structure'를 잘 이용하기 위해선, image로부터 자동적으로 scene graph를 생성하는 모델을 고안하는 것이 중요합니다.
=> Goal : generate a visually-grounded scene graph from an image
생성된 scene graph에선, object instance가 object category label을 갖는 bounding box에 의해 특성이 부여되고, 그들간의 관계는 2개의 bounding box간에 존재하는 relationship predicate을 갖는 directed edge에 의해 특성이 부여됩니다.
scene graph를 생성하는 데에 가장 중요한 문제는 '관계들에 대한 추론'입니다.
semantic relationship을 구역화하고 인식하는데에 많은 연구가 진행되었지만, 대부분의 방법들은 object relationship의 'local' prediction을 만드는 데에 집중이 되었습니다. 그리고 이는 scene graph를 단순화해 object들의 pair들간의 관계를 독립적으로 예측하도록 하는 문제를 야기합니다.
그러나 이 논문에 나온 방법에선, local prediction을 할 때 surrounding context를 무시하기 때문에, contextual information을 갖는 joint reasoning은 각각에 대한 local prediction으로 인해 ambiguity를 해결할 수 있습니다.

Related Work
Scene understanding and relationship prediction
visual scene을 추론하기 위해 object co-occurrence의 statistical pattern뿐만 아니라 spatial layout도 사용해왔습니다. 지금까지의 방법들은 relationship prediction에 복잡한 구조를 사용했지만, 디테일한 시각적인 근거 없이 image-level 예측에 초점을 맞췄습니다. 실제로 long-tail distribution에 대한 prior를 다루기 위해 input에 language(text)와 visual input을 결합해 semantic relationship detection도 이뤄졌습니다. 그러나 이런 방법은 독립적으로 각각의 relationship을 다루기 때문에, 이 논문에선 관계들간의 joint inference를 이용해 성능이 좋은 model을 제시했습니다.
Visual scene representation
visual scene 표현하는 가장 대표적인 방법은 text description을 이용하는 것입니다. text-based representation이 물론 scene classification과 retrieval에선 도움이 되지만, ambiguity나 expressiveness에 어느정도 한계가 있습니다. 또 다른 방법은 scene graph인데, scene graph는 visual concept에 대한 explicit한 근거를 제공하기 때문에 text-based representation에서 발생하는 referential uncertainty를 방지할 수 있습니다. scene graph를 사용한 이전 연구는 (1) ground-truth annotation을 사용하거나 (2)다른 modality에서 graph를 추출하는 방식으로 'graph generation' 문제를 피해왔습니다. 이를 해결할 수 있도록, 논문에선 image로부터 scene graph를 바로 생성하는 문제를 다루고자 했습니다.
Graph inference
graph inference에선 CRF(Conditional Random Fields)가 광범위하게 사용되어왔습니다. CRF를 image retrieval을 위한 scene graph grounding distribution을 생성하기 위해 사용하거나, 상황에 기반한 obejct와 action prediction에 사용하기도 했습니다. 논문에선 CRFasRNN이나 Graph-LSTM에서 사용한 것과 비슷하게, RNN 기반 model을 사용해 graph inference문제를 공식화했습니다. 다른 점은 edge를 pairwise constraints로 다루면서 node inference에 집중한 것과 달리, 논문에선 primal-dual graph inference scheme을 사용해 edge prediction을 가능하도록 했습니다. 또한 Structural RNN과 비슷한 목표를 갖고 있지만 중요한 차이점이 있는데, 이 model은 message passing을 통해 반복해서 prediction을 정제하지만, structural RNN은 temporal dimension(시간 축)을 따라 한 번만 예측하기 때문에 과거의 prediction을 정제할 수 없습니다.
Scene Graph Generation
한 정의에 따르면 scene graph는 node가 category를 포함한 object의 bounding box가 되고, edge는 object간의 pairwise relationship이 되는, image의 구조화된 representation입니다. 직관적으로, object들과 relationship들의 각각의 prediction은 주변 문맥 상에선 도움이 될 수 있습니다. "horse is on grss field"를 알고 있다면, object로서 person을, 그리고 이 둘의 관계를 "man riding horse"에 대한 prediction의 chance를 높일 수 있습니다. 이런 intuition을 얻기 위해선, contextual 정보가 scene graph topology로 전파될 수 있도록 해야 합니다. ( message passing scheme 이용)
(효율성 측면)
비용이 많이 드는 densely connected graph를 사용하는 대신 sub-graph들 간의 message들을 반복적으로 passing하면서 inference 효율성을 높일 수 있습니다.
Problem Formulation
시각적으로 근거가 있는 scene graph를 생성하기 위해, object bounding box들의 초기 set을 얻어야 합니다. 실제로 이 논문에선, inference 단계에서 bounding box의 set을 자동적으로 생성하기 위해 RPN(Region Proposal Network)를 사용했습니다. (image I -> B(i))

n개의 bounding box가 주어졌을 때, x는 이에 대한 모든 variable을 포함하고 있습니다. i번째 bounding box에 해당 class label과 bouding box offset이 있고, i번째 bounding box와 j번째 bounding box간의 관계(relationship)도 포함합니다.

우리는 image I와 image I에 대한 bounding box proposal B(I)가 주어졌을 때, 이에 일치하는 x를 예측하는 probability를 높이는 x를 찾아야 합니다.

probability를 구체적으로 적어보면 다음과 같습니다.
다음 section에선 inference procedure을 approximate하기 위한 Gated Recurrent Units로 modeling된 iterative message passing scheme을 알아보겠습니다.
Inference using Recurrent Neural Network
approximate inference를 수행하기 위해 mean field를 사용했습니다.
각 variable x의 probability를 Q(x|.)로 정하고, 이 때 probability는 매 iteration에서의 각 node와 edge의 현재 state에만 의존한다고 가정합니다. hidden state를 계산하기 위해서 일반적인 RNN module 중 하나는 GRU를 사용합니다. 모든 node들은 같은 update rule를 공유하기 때문에, 모든 node들에 대해 같은 parameter set을 공유합니다. (edge도 마찬가지)
node i가 있고 node i와 node j간의 edge i->j가 있을 대, node의 hidden state는 h(i), i->j의 hidden staten는 h(i->j)라고 합니다.

위의 식은 mean field distribution으로 정의된 식입니다.
이 때 f는 각각의 visual feature를 의미합니다.
proposal box의 visual feature를 i번째 node에 대한 visual feature f(i)로 사용하게 됩니다. f(i->j)처럼 edge에 대한 visual feature는 proposal box b(i),b(j)가 있을 때 이 둘의 union box의 visual feature로 사용합니다. 이런 visual feature는 image로부터 ROI pooling layer에서 뽑을 수 있습니다. 이후의 iteration에서는 이전 step의 GRU unit들로부터 message가 통합됩니다. 그렇다면 message들은 어떻게 합쳐지고 통합될까요?
Primal Dual Update and Message Pooling
위에선 RNN를 사용해 graph inference 문제를 해결하기 위한 일반적인 formulation을 알아봤지만, scene graph의 unique한 bipartite 구조를 활용하면 inference efficiency를 높일 수 있습니다. scene graph topology에 따르면, edge GRU의 neighbor은 node GRU이고 그 반대도 성립합니다. 이런 구조를 따라 message를 전달하는 건 서로에게 dual graph가 되는 2개의 disjoint sub-graph를 형성하게 됩니다.
더 자세히 설명하면, node중심의 primal graph에선 각 node GRU가 inbound, outbound edge GRU로부터 message를 가집니다. edge중심의 dual graph에선 각 edge GRU가 subject node GRU와 object node GRU로부터 message를 얻습니다. 그렇게 되면, densely connected graph를 사용하는 대신 2개의 sub-graph간의 message들을 주고받으며 inference efficiency를 향상시킬 수 있습니다.
각각의 GRU에는 여러개의 message가 들어오기 때문에, 모든 message들로 의미있는 representation으로 만들기 위해 정보를 합칠 수 있는 aggregation function이 필요합니다. naive하게 average나 max-pooling같은 전형적인 pooling 방법을 사용해도 되지만, 여기선 adaptive weight를 학습시키는 게 더 효과적이라고 판단했습니다. 이 방법을 사용하면 들어오는 message들의 영향을 조정할 수 있고 관련있는 정보들만 유지할 수 있습니다. 'message pooling' function을 통해 들어오는 각각의 message들의 weight factor를 계산하고 weighted sum을 통해 message를 합칠 수 있습니다.
node와 edge의 current GRU hidden state가 주어졌을 때, i번째 node를 update하는 message를 m(i)라 하고, 이 message는 hidden state h(i), outbound edge GRU의 hidden state h(i->j), inbound edge GRU h(j->i)들에 대한 function으로 계산됩니다. 비슷하게 i-node에서 j-node로 가는 edge를 update하는 message를 m(i->j)라 하고, 이는 hidden state h(->j), subject node GRU hidden state인 h(i), object node GRU h(j)에 대한 function으로 계산됩니다.
식은 다음과 같습니다.
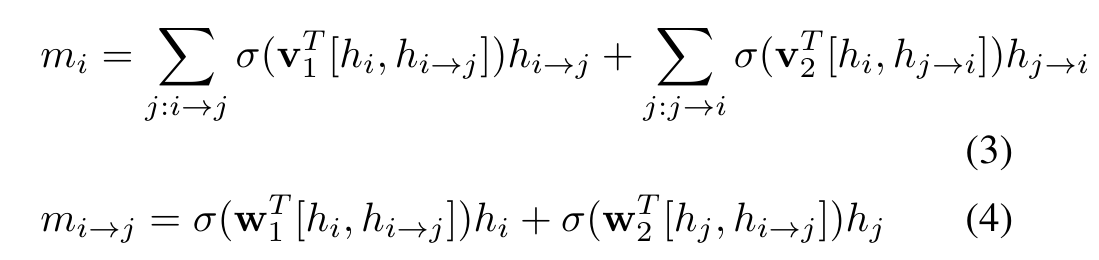
여기서 [.]는 vector의 concatenation을 의미하고, sigma는 sigmoid function을 의미합니다.
w1,w2,v1,v2는 learnable parameter입니다.
이 두 equation은 primal-dual update rule를 사용합니다.



